


杠杆炒股,股票融资!

发布日期:2025-01-24 17:49 点击次数:180
剪辑:剪辑部 HYZ
医疗AI期间认真开启!百川刚刚用Baichuan-M1-preview交出了一份惊艳答卷,用医疗循证形态重构AI+医疗的领域。更惊喜的是,首个医疗增强模子BAIchuan-M1-14B开源了。
就在刚刚,百川的首个全场景深度想考模子Baichuan-M1-preview发布了!
比较其他推理模子,它才气全面,同期具备谈话推理、视觉推理、搜索推理三个维度的全面推理才气,且均作念到了行业逾越。
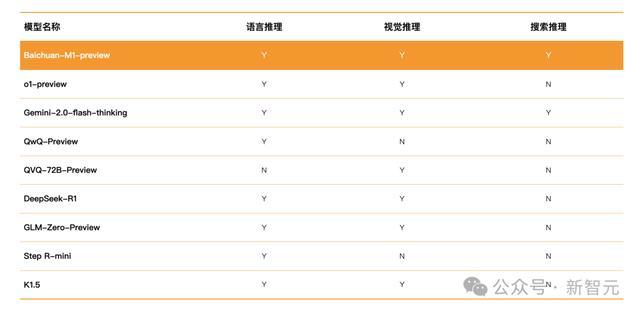
而且,还解锁了「医疗循证形态」,复杂医疗问题的推理才气大幅升迁。
咫尺,M1仍是在百小应上线了。
具备深度想考形态的百小应,不仅能准确解答数学、代码、逻辑推理问题,还能会像资深医疗群众同样,进行深度想考,构建出严谨的医学推理过程。
不仅如斯,为了推动AI本领在医疗领域的立异发展,茂密AI医疗生态,百川还开源了Baichuan-M1-14B。
便是这个M1的小尺寸版模子,医疗推理才气仍是超过了更大参数目的Qwen2.5-72B,与o1-mini出入无几。
全场景深度想考模子,通用才气行业逾越
Baichuan-M1-preview行为推理模子,异常擅长通过深度想考来解决复杂的推理问题。
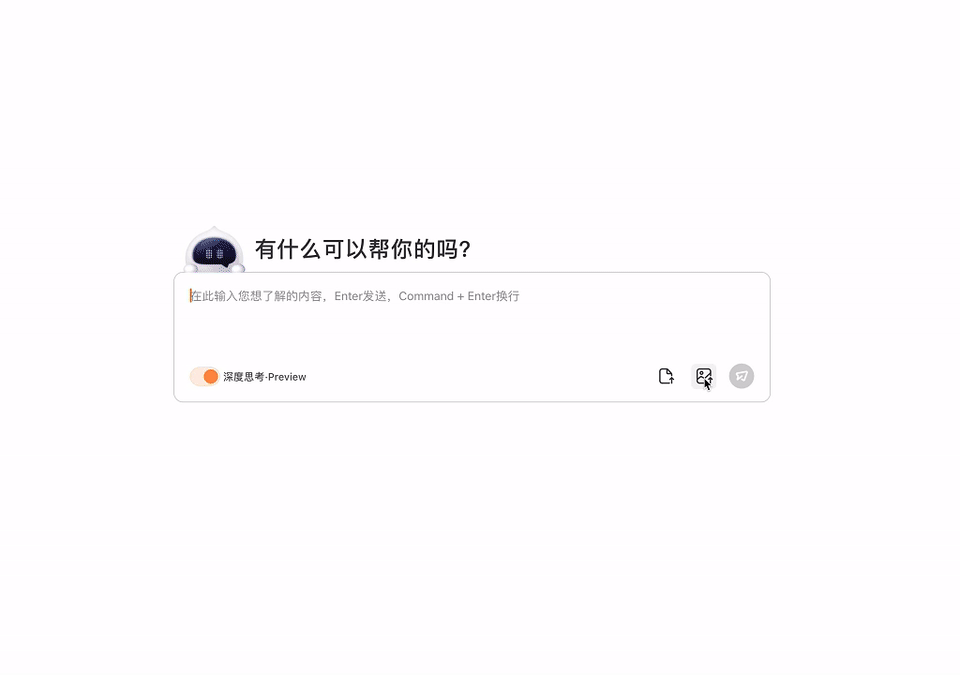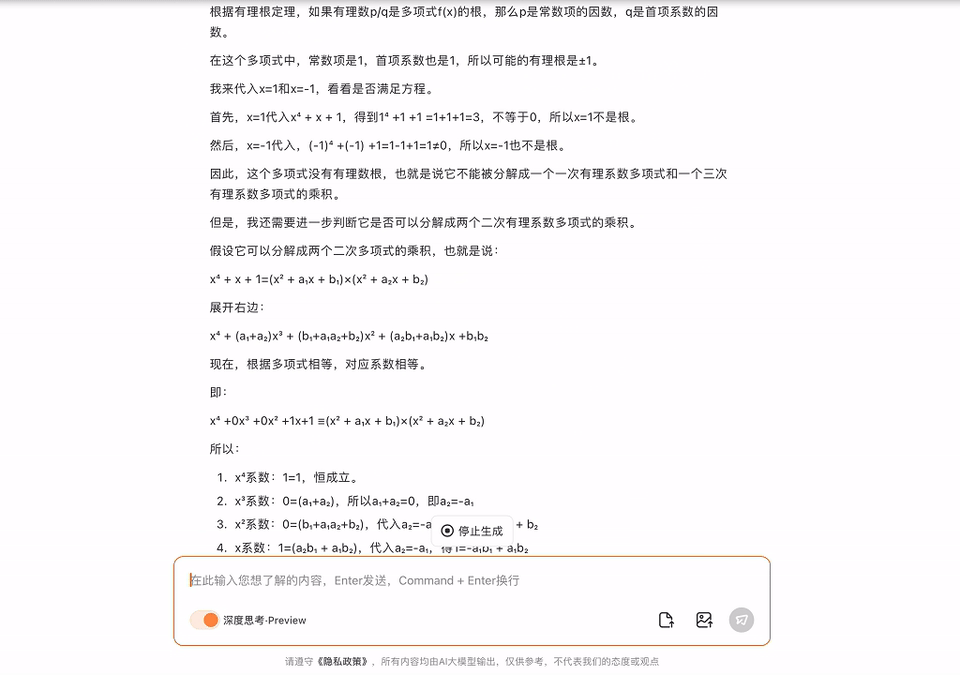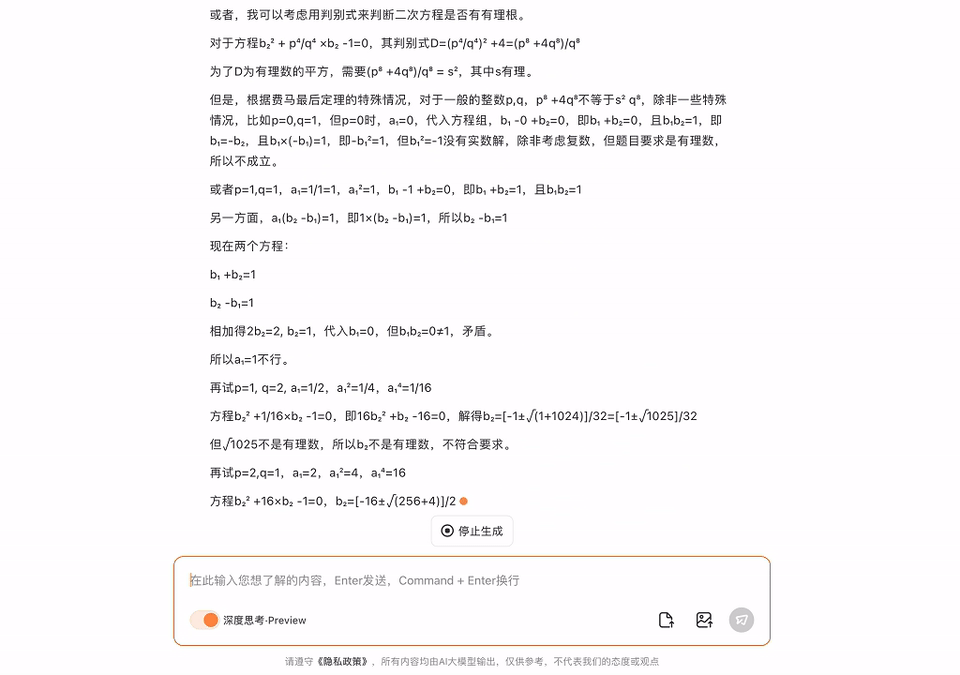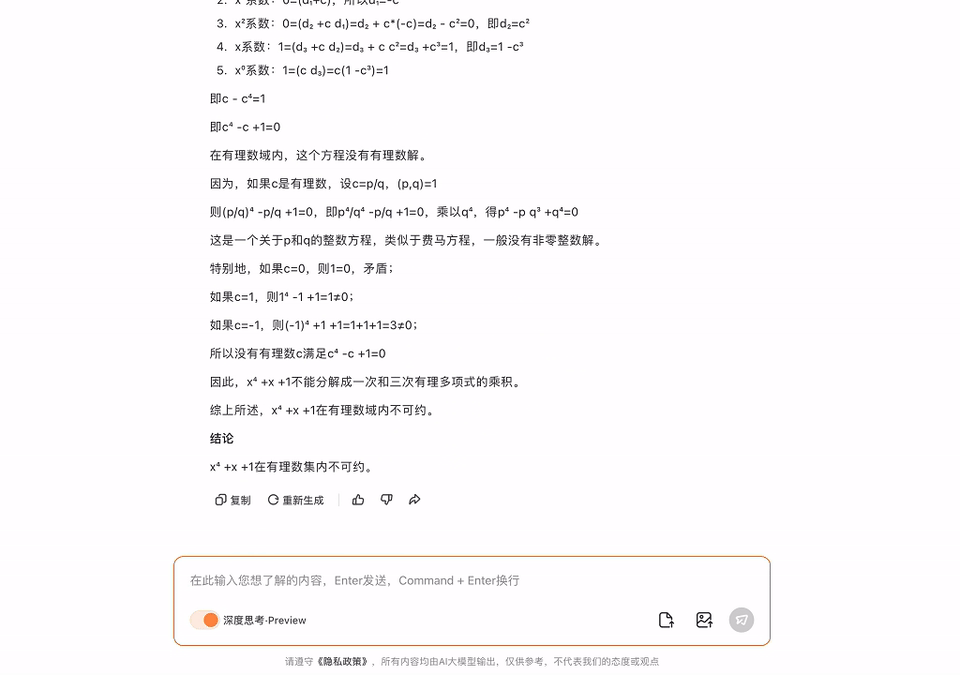
给出一个式子,问在有理数集内是否可约?同期还要给出判断和讲解。
模子准确识别出了图中的问题,何况班师给出了正确谜底。
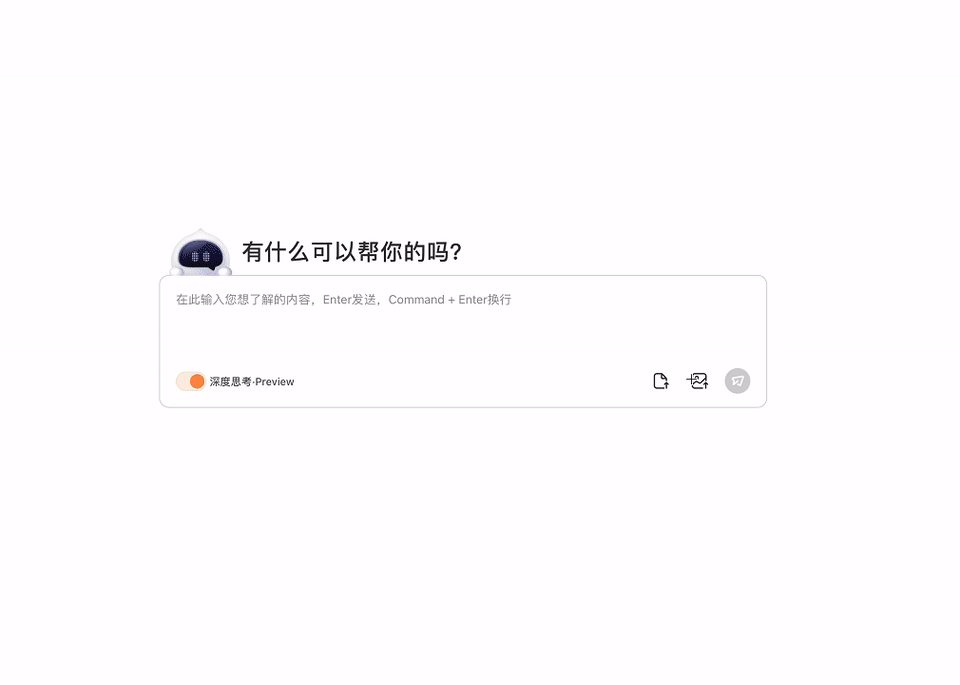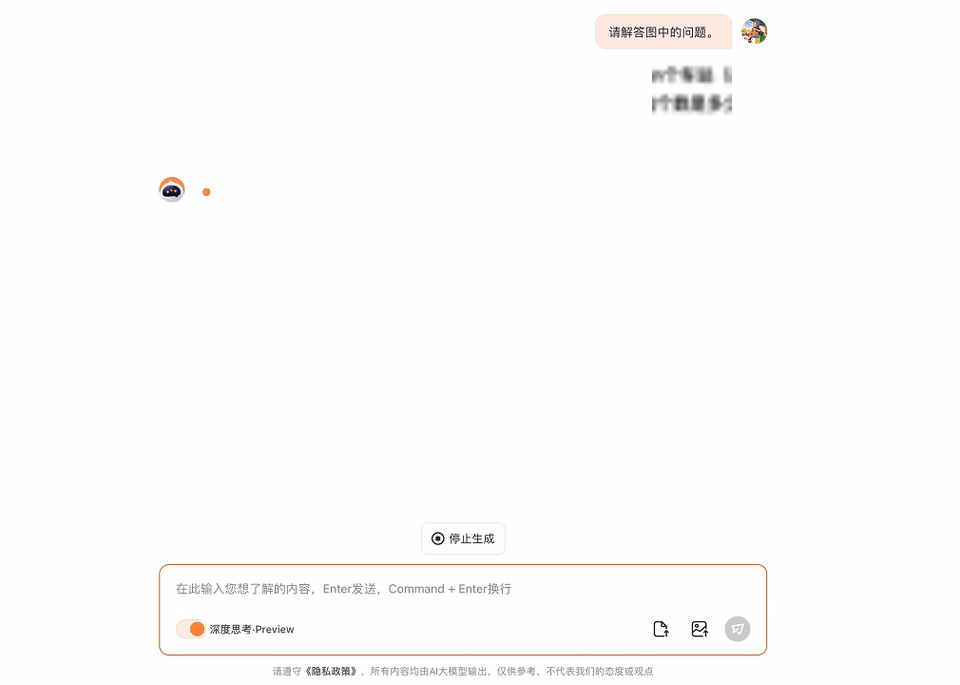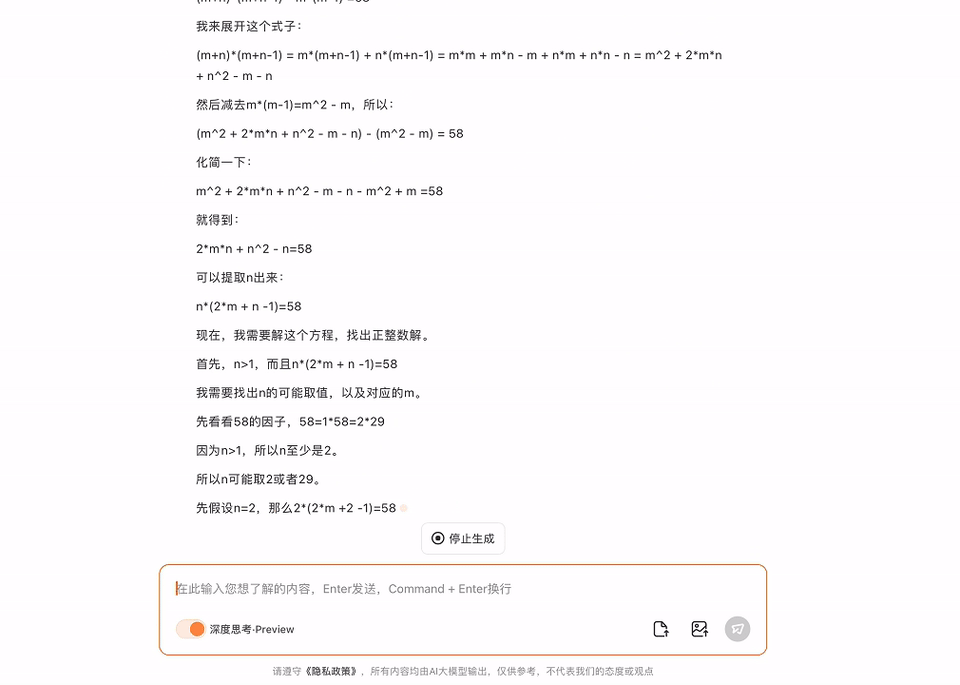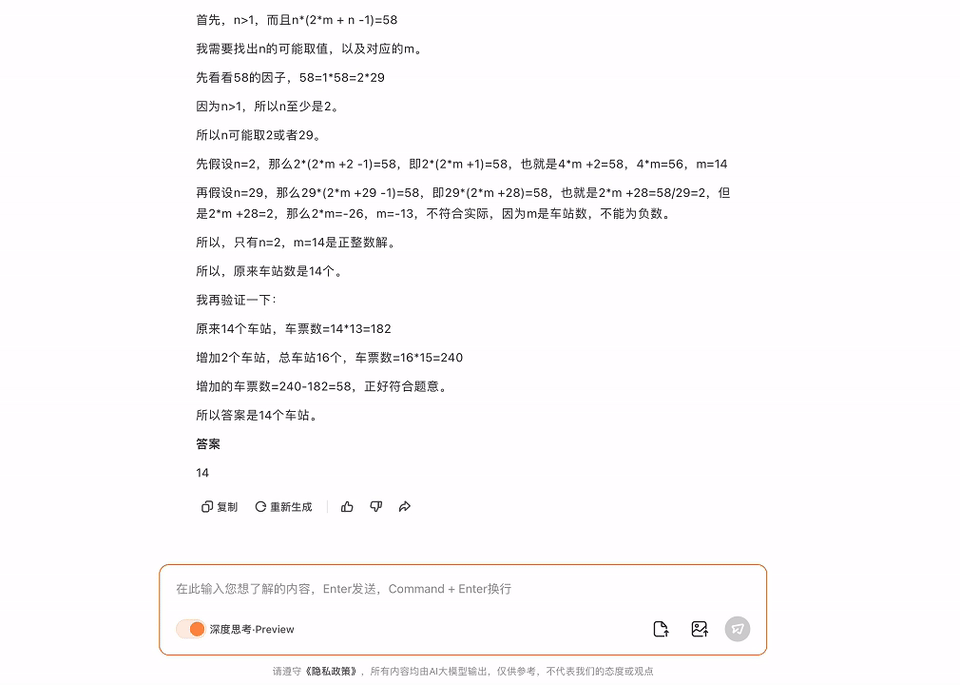
一条铁路原有m个车站,为适应客运需要新增多n个车站(n>1),则客运车票增多了58种(注:从甲站到乙站需要两种不同的车票),那么原有车站的个数是若干?
这个数学应用题,它经过一番推理,也给出了正确谜底。
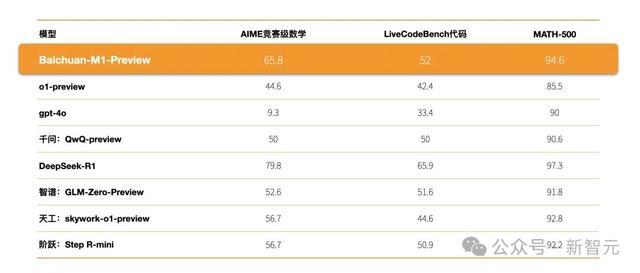
Baichuan-M1-preview在各式评测中的收获也异常优秀。
在AIME和Math等数学基准测试,以及LiveCodeBench代码任务上,它的收获超过了o1-preview等模子。
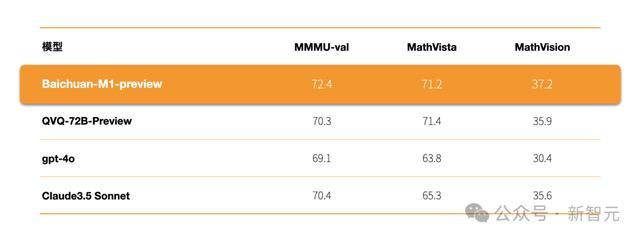
视觉推理才气方面,在MMMU-val、MathVista等泰斗评测中的收获,它也超过了GPT-4o、Claude3.5 Sonnet、QVQ-72B-Preview等模子。
不错说,这是百川智能在探索大模子深度推理才气谈路上达到的垂危里程碑。
通过立异的RL门径,百川智能赋予了M1更巨大的推理和琢磨才气——像东谈主类同样永劫刻想考,在推理过程中连续自我反想和调动,根据问题本性生动颐养解决决策。
而模子的深度想考才气,也让它在学术讨论、软件开发、医疗健康等领域展现出显耀的特有上风。
更令东谈主欣喜的是,M1的显式想维链为大模子的可解释性掀开了一扇窗口!
从此,咱们大略跟踪和侵犯模子推理过程和决策依据。
这不仅升迁了模子委果度,更为大模子在医疗等高度专科领域的落地应用,指明了标的。
解锁医疗循证形态,医疗才气显耀升迁
Baichuan-M1-preview的另一大亮点是解锁了「医疗循证形态」。
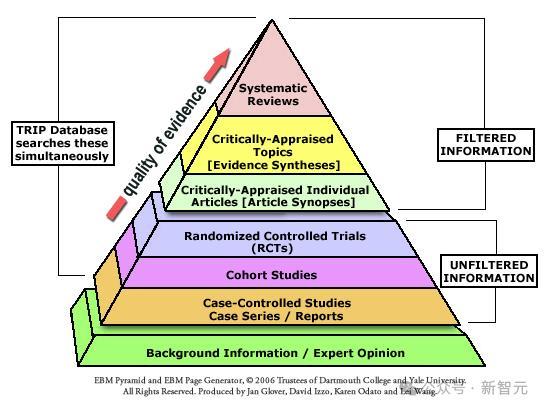
所谓医疗循证形态(Evidence-Based Medicine, EBM),是一种医学诊疗门径。
它将把柄依知识论上的强度分类,并要求唯有强度最高的把柄(如元分析、系统性评述和立地对照老到)才能归纳为有劲的提议把柄;相对较无力的把柄(如群众意见、动物实验、细胞实验、基快乐趣推行)只可归入有劲进度不高的提议。
循证医学主张,决策和计谋应尽可能根据把柄,而非单单依据从业东谈主员、群众或经管者的信念。
因此,它试图确保临床医师的意见,有基于科学文件的悉数可用知识补足,保证管事为最好诊疗。
就像循证医学同样,Baichuan-M1-preview的「医疗循证形态」,要先开拓医学知识数据库,然后在医疗知识库和互联网的信息上进行推理。
不仅如斯,医疗循证形态还能应用医学知识和把柄评估法子,对把柄进行多层分级,并对不同泰斗等第的把柄进行专科分析与整合,识别各种泰斗信息的着手和委果度。
这样,模子在面临复杂问题,以及信息过载、不坚信性和碎屑化等痛点时,便能用专科可靠的医疗知识行为推理依据。
海量医疗知识库,主动搜索泰斗信息
为了完毕这少量,团队当先构建了一个涵盖亿级条主张自建循证医学知识库,其中囊括了国表里海量医学论文、泰斗指南、群众共鸣、疾病与症状通晓、药品证实等中枢执行,并完毕了天级别的动态更新。
与此同期,团队还针对海量的医学信息,构建了一个多层级把柄分级体系。完毕了期刊质料、讨论门径、同业评审严谨度等多个维度的合资甄别、溯源与评级。
在推理过程中,M1会对复杂的医学问题开拓起系统性的推想象路,并自主调用搜索才气来赢得最新的泰斗医学把柄、临床指南和讨论进展。
而在面临海量、多源的医学信息时,M1则会充分证实强化后的推理才气,通过识别各种泰斗信息的着手和委果度,对不同泰斗等第的把柄进行专科分析与整合。
当发现潜在的冲突和不一致之处,它还能长远剖析不同把柄的完了条目,甄别出最干系和委果的论断。
通过这种专科的分析,模子就能灵验地解决信息冲突,造周密面、连贯的医学论断,进而完毕可靠、准确的医学推理,最终提供委果赖的医疗谜底。
大夫的助手,患者的照拂人
Baichuan-M1-Preview解锁的医疗循证居品,不仅是大夫和医疗专科东谈主士的可靠助手,亦然患者的贴心健康照拂人。
它能通过「摆事实、讲真理」的循证面目,提供言之有物、有理有据的解答,又快又准。
大夫和医学生,再也无须为复杂病例发愁了。这个临床场景中,最近有什么新科研后果?想了解泰斗指南?平直一键科罚!
无须再翻书、查贵府了,省时又省力。
关于想搞医学科研的东谈主,它也几乎是神器一枚。最前沿的讨论后果,快速构建知识体系,用这个居品都能谈何容易。论文、指南,完满秒查。
关于患者来说,亦然大大的好音尘。
看不懂大夫复杂且专科的查验阐发,却想更全面解读查验完了,或者想来一个「二次会诊」?咫尺不错省略完毕了。
以致,它不仅能帮你了解查验阐发上说了啥,还能让你跟大夫换取的更顺畅,更好地参与颐养决策!
而在科普健康知识上,它的效果亦然一流,让你在颐养路上不再是被迫接招的小白。
总之,这个让医疗更精真金不怕火、更透明的医疗循证居品,无论对大夫、医学生和患者,都是一个万能神器。
万亿级token教练,首个医疗增强14B开源
并吞天,百川智能还开源了医疗增强通用大模子Baichuan-M1-14B。
行为行业首个医疗增强开源模子Baichuan-M1-14B的弘扬优异,不仅在cmexam、clinicalbench_hos、clinicalbench_hos、erke等泰斗医学知识和临床才气评测上的收获超过了更大参数目的Qwen2.5-72B-Instruct,与o1-mini也出入无几。
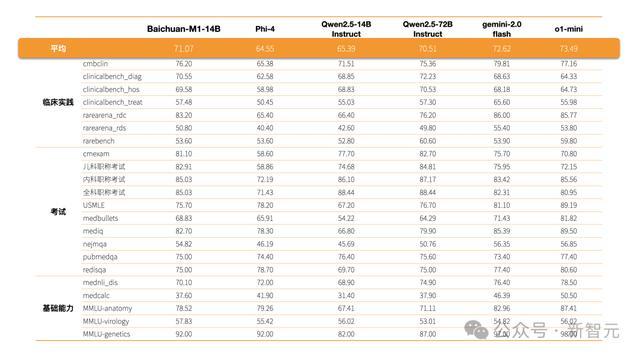
能以这样小的参数目在医疗领域称霸,其实力防碍小觑。
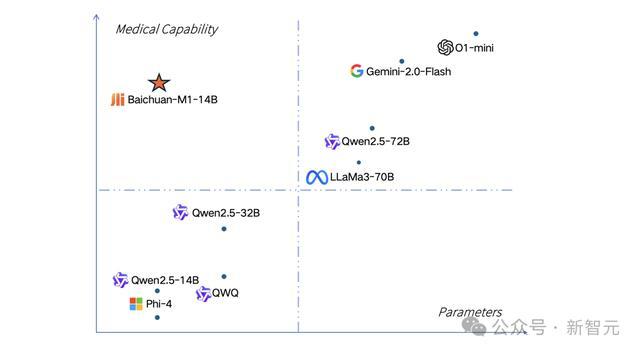
它的本领亮点,体咫尺数据汇集及合成,股票投资以及模子教练上。
数据汇集
Baichuan-M1-14B总额据量高达万亿级token,相当于把一所超大型医学藏书楼的执行,一起装进了「大脑」里。
具体来说,在数据汇集阶段,百川团队针对医疗场景作念了异常概括的汇集,障翳了广阔公开和非公开数据:
千万级中/英文专科医疗论文;
千万级院内真的中/英文医疗病例;
万本医疗课本、几十万级医疗竹素;
千万级知识图谱医疗实体、百万级医疗词条;
百万级指南、群众共鸣、知识库等专科数据;
亿级医疗问答、医疗问诊、临床看病数据;
汇集还只是是第一步,他们还对全网数据进行了全面的分类和评估,包括医疗科室、医疗执行、 医疗价值领域。
在预教练阶段,严格的数据筛选是必不可少的。
鉴于此,团队确保了数据集聚各科室数据均匀辨认,何况包含了真确正确的医疗价值信息。
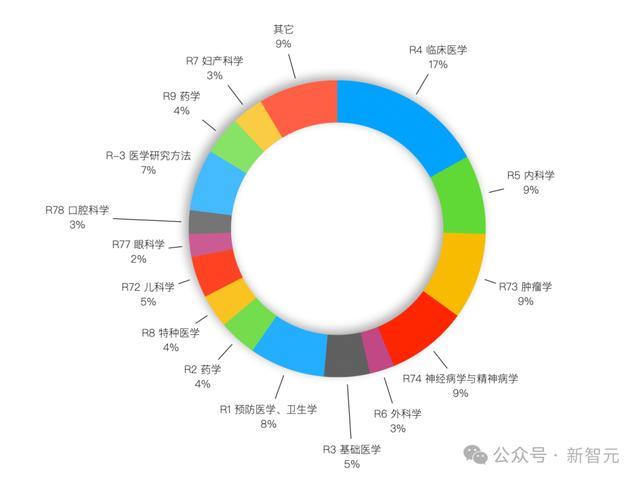
数据医疗科室分类
合成数据
在强化学习部分,团队主要使用了合成数据。原因在于,合成数据中包含医疗复杂决策推理链条、决策依据以及问答对体式,大略较好地升迁模子的临床分析、推理和决策才气。
百川团队对每种类型的医疗数据,遐想了针对性的数据合成决策。
这些数据障翳了知识图谱、病例、课本、指南、知识库、群众共鸣、问诊纪录、学术论文等领域。
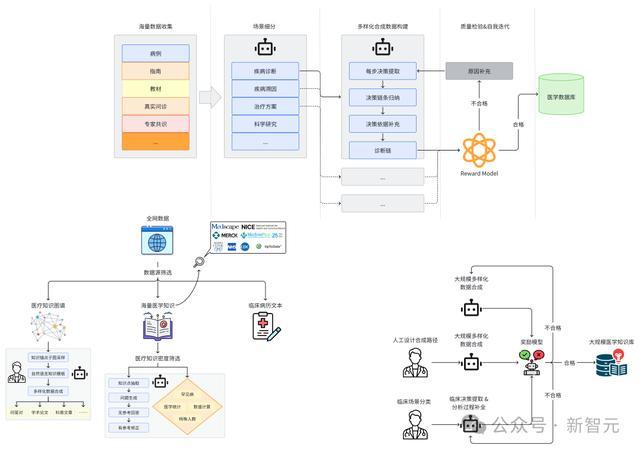
除了让模子广阔学习医疗知识,团队还基于临床病历文本,利用早先进的模子模拟东谈主类医师的想维过程。
然后,基于自我反想机制和奖励模子(Reward Model),生成了超千亿 token的医疗复杂决策推理链条、决策依据以及问答对体式的各种化数据。
模子教练
Baichuan-M1-14B的教练门径,也超硬核。
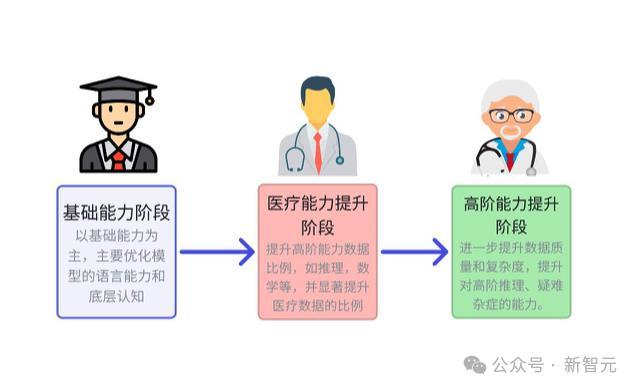
百川应用行业创始的多阶段领域升迁决策,将教练过程奥秘看法为「三步」策略——通识升迁、医疗基础知识升迁、医疗进阶知识升迁。
阶段一,让模子掌合手基础的谈话才气、知识才气。
阶段二,在第一步基础上,进一步强化模子的高阶才气(比如推理、数学等),并显耀升迁医疗数据比例。
这相当于,让一个刚毕业的医学生,上专科课的过程。
阶段三,则进一步升迁数据质料和难度,对其更高阶的医疗才气,如推理、逻辑、疑难杂症等,进行深档次优化。
对皆
在针对LLM的强化学习教练中,数据的质料与各种性是模子性能升迁的要道。
为此,团队从多个领域经心汇集、整理了偏序对数据,障翳了平凡的应用场景,包括多轮对话、教唆奴婢、数学与代码、推理任务。
而为了增强数据的各种性与真的性,数据着手包括东谈主类生成数据和多模子生成数据。
另外,团队还汇集了约100万条偏好数据,明确标志出完了中的优劣偏好。
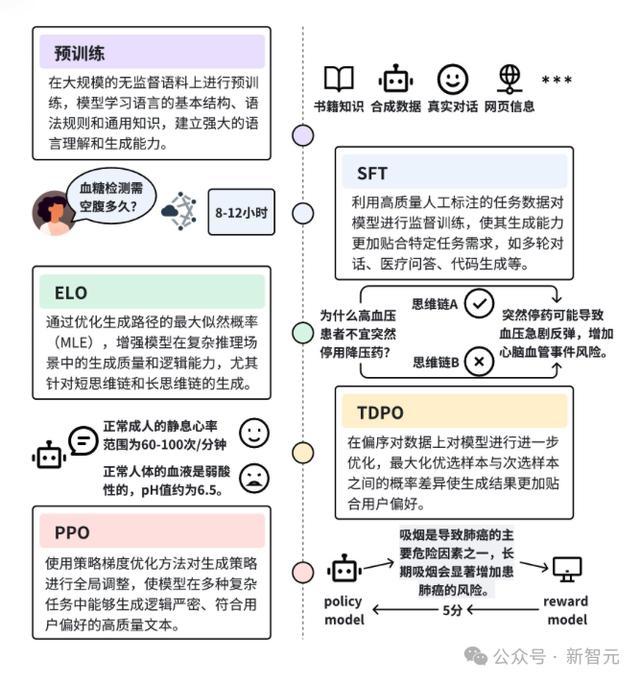
何况,为了进一步升迁模子的生成质料、逻辑推理才气和用户偏好贴合度,团队遐想了一套系统化的强化学习(RL)教练进程。在SFT模子基础上,他们分三步缓缓优化。
具体进程如下:
1. ELO(Exploratory Log-likelihood Optimization)进行想维链探索
传统的强化学习门径,时时依赖于「奖励模子」,但这里团队则别有肺肠——
在CoT教练框架中,引入了全新的算法ELO。
它的绝妙之处在于,大略大幅升迁模子的生成质料和逻辑推理才气。
ELO算法的中枢想想是,通过优化想维链旅途,来提高response的最大似然概率。
在传统门径中,reward model可能引入的偏差,会影响最终模子的性能。而ELO通过平直优化逻辑旅途,则平直幸免了这一问题,确保了教练过程愈加谨慎。
何况,通过强化MLE指标,ELO还能在保持生成执行各种性与合感性的同期,确保生成文本的高概率准确性。
2. 基于偏序对数据使用TDPO(Token-level Direct Preference Optimization)门径对模子进行优化
表面分析标明,在DPO的优化框架中,KL散度项用于不竭生成模子与参考模子之间的辨认互异。
但是,由于KL散度的不竭效应跟着句子长度变化不平衡,其对短句的不竭较强,而对长句的不竭则显耀削弱。
这种不平衡可能导致生成模子在长句生成过程中偏离参考模子,从而影响生成完了的逻辑性与质料。
最终,团队采纳了蓄意遵守与性能兼备的TDPO,行为偏序对数据优化的中枢门径。
在ELO教练之后的模子基础上,团队进行了一轮的TDPO教练,确保模子大略精确贴合用户偏好,同期兼顾黑白句子的生成质料。
3. 最终阶段,摄取PPO(Proximal Policy Optimization)门径进一步优化模子的生成策略
PPO充分利用了ELO和TDPO阶段的优化后果,将模子的生成策略从局部的Token级别优化彭胀至全局的策略颐养,确保模子大略在多种任务中生成合适用户需求的高质料文本。
这套教练门径,就像是为LLM量身定制的「成长隐讳」,通过精细数据筛选、多阶段优化,推动Baichuan-M1-14B向着更智能方上前进。
开源,意味着什么?
正如Llama同样,模子的每一次开源,都让AI领域连续拓展,激勉了更多领域的立异。
Baichuan-M1-14B的开源,也不例外。
它不单是是一个模子的开源,更像是为悉数这个词医疗行业掀开了一扇大门。
因此,关于开发者来说,这透顶是一个不行错过的模子。
在医疗AI领域,许多本领都被「深藏闺中」,面向医疗类的垂直领域,这类巨大的模子少之又少。
而百川选拔开源,便是要冲突这谈墙。
Baichuan-M1-14B开源,大略让路发者平直战斗到医疗AI背后本领,裁减应用开发门槛,以致大略加快该领域的迭代升级。
如上所述,Baichuan-M1-14B领有一个装载海量医疗知识的「超等大脑」。
开发者不错基于此开发出更多的医疗应用,比如智能问诊助手、医疗文件智能检索器具、临床决策系统等等。
另一方面,医疗领域最垂危的便是透明度、委果度。开源还意味着,本领完毕了完全透明,AI社区开发者不错共同审查和改进。
而这种透明度,是推动开拓医疗AI委果度的基石。
从更长期来看,当一项巨大的医疗AI被开源,意味着它将会走向普惠,走向每个东谈主。
下层病院不错提供更优质的管事,关于那些偏远地区,也有契机用上先进的AI医疗本领。
将来,更多东谈主也能享受到AI带来的医疗福利。
还需强调的是,这一次,Baichuan-M1-14B开源并非是百川的「独奏」,而是医疗AI领域的「交响乐」。
他们开释出了一个明确的信号,鼓吹医疗AI生态共建。
医疗AI的将来,不应该是冷飕飕的代码,而是让每一次诊疗都充满温度。