


杠杆炒股,股票融资!

发布日期:2025-02-16 13:30 点击次数:64
【编者按】当一项技能成为时局级话题,信息过载往往带来默契包袱。DeepSeek的赶紧崛起催生出海量解读,但实在具备信息增量的内容可能不足千分之一。腾讯科技以“价值密度”为筛,从全球视线筛选出5-10篇兼具技能纵深感与行业前瞻性的深度分解,为关注AGI进度的读者过滤杂音、索要精华。
作家 Monica.im居品结伴东说念主 张涛

最好的请安是学习
本年春节,我在上海过年,莫得回重庆,就通过视频给爸妈贺年。我给我妈说新年开心时,听到我爸在操纵喊说念:「你快问一下张涛,阿谁梁文锋是不是果然那么给力啊?」
本年的 DeepSeek 和 R1 话题果然是破圈的程度相当高,甚而像重庆这样的二线城市的老翁老浑家们都在关注这些话题,且由衷热心它背后的旨趣到底是什么。
起先咱们回来一下这些发生的事情,理清时分线,确保寰球对这个事情有共同的默契。

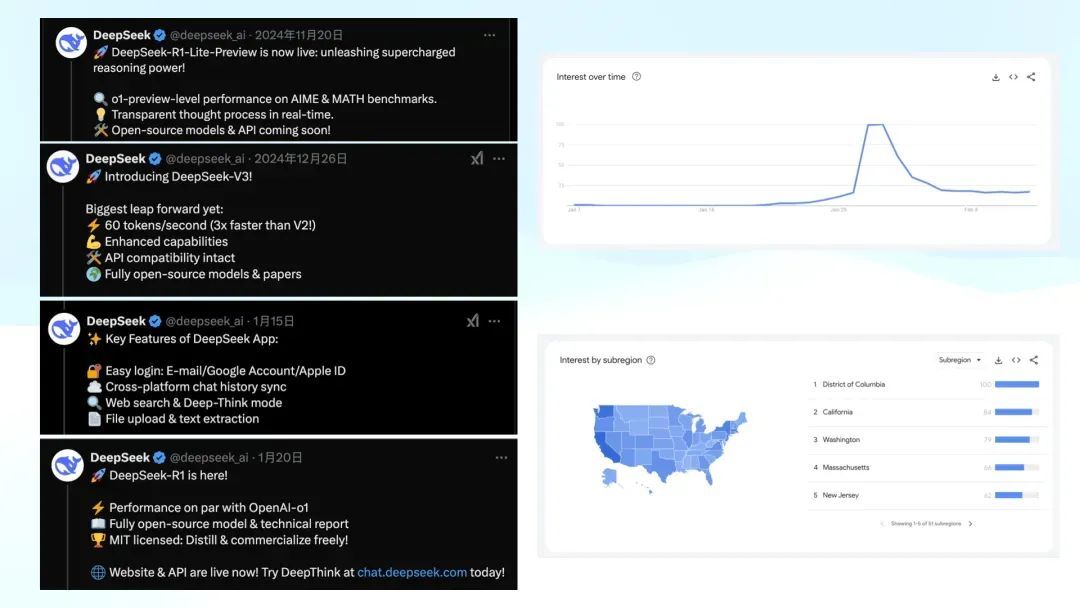
旧年 11 月 20 日,DeepSeek 在官方 Twitter 上发布了 R1 Lite Preview。那时发布的 R1 Lite Preview,真话说,离当今的影响力连 1% 都谈不上,可能只须万分之一。只须旧年 11 月 o1 发布后,有一些东说念主试图复现 o1,这时他们可能对这个 R1 Lite Preview 感风趣,甚而有东说念主基于它进行一些蒸馏和 SFT 的服务。但这些服务在学术界里面并未出圈。
接着到 12 月 26 日,发布了 DeepSeek V3。比拟 R1 Lite Preview,它的影响力就更大了一些。稍后我会举一个例子诠释,至少在学术界,它是有出圈的。
第三个时分点是 1 月 15 日,DeepSeek 发布了他们的 APP。那时如果寰球仔细看,会发现 15 号发布的 APP 中,已经有了 DeepThink 模式。
但是 DeepThink 这个模式一直无东说念主介意,国内莫得,国外也莫得。如果寰球能回到 15 号的语境下,其实可以知道为什么。那时不仅是好意思国,包括咱们在内,寰球关注的新闻基本只须一个——特朗普行将登基。公众的珍观点还更多汇注在这些政事事件上。直到 20 号,R1 才正经发布,一方面是有关论文公开,另一方面是模子权重的开源。
从时分线来看,R1 最早的苗头施行上在旧年 11 月份就已经出现,并非整宿之间爆发的。在这个经由中,还有几个枢纽节点需要关注,包括 V3 的迫切性——这是咱们今天规划的中枢话题之一。
接下来,我给寰球看一个羡慕的时局。在 Google 上搜索 DeepSeek 这个枢纽词,可以看到其关注度的起初是在 1 月 20 号,也就是 R1 发布之后。跟着学术界运转小范围规划,20 号到 24 号、27 号之间热度逐步升温,直到 27 号,英伟达及一众好意思国 AI 倡导股「砸出巨坑」,DeepSeek 的搜索量也随之达到顶峰。即使热度在一周后有所回落,比拟 20 号之前接近 0% 的状态,当今仍然督察在 20% 傍边。这确认,尽管流量有所回调,但关注度并未全都消退。
接下来是一个羡慕的话题,不知说念寰球能不成猜到:在好意思国,按行政区域分散,哪个地区对 DeepSeek 关注度最高?
我那时在看数据时合计相当专诚想。本以为会是加州,毕竟 AI 有关研究东说念主员主要汇注在何处,但施行上,最高关注度出当今华盛顿特区。可以联想,在 27 号市集触动后,华盛顿的一众政客猖獗在 Google 上搜索 DeepSeek 试图搞明晰 DeepSeek 到底是个啥?
之后的名次则较为正常:加州、华盛顿州这些传统 IT 公司和 AI 研究机构汇注的地区关注度较高。但 DeepSeek 这样高的关注度如实值得一提。
前边咱们规划的是发布方的反应,当今来看好意思国社会中精英 KOL 们的反馈。寰球可能还铭刻,我之前提到,12 月 26 号 V3 发布时,比拟 R1 Lite Preview,此次在学术圈实在「破圈」了。
为什么这样说?可以看这张图,右侧是 Andrej Karpathy 的 Twitter。今日,他发布了一条相当长的推文,详细先容了 V3,并评价其为「very nice and detailed tech report(相当出色且详细的技能禀报)」。可以细目标是,12 月 26 号 V3 发布时,它已赢得好意思国主流学术圈的认同,只是那时许多东说念主尚未意志到 V3 的更深眉目价值。
咱们再回到春节时期的「炸街」时刻。
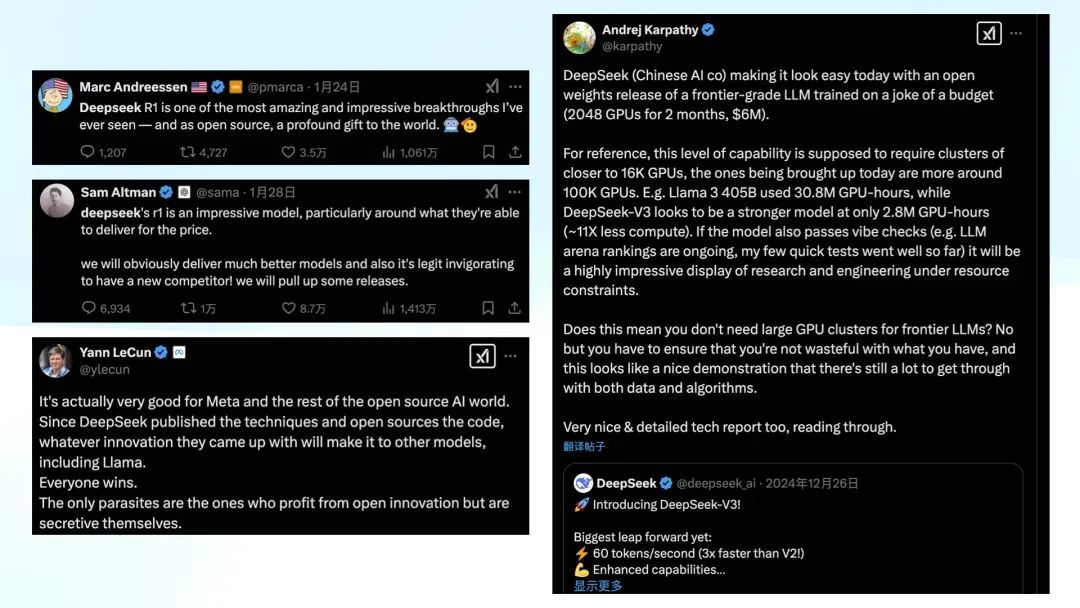
第一次让我意志到好意思国公论运转转化的节点是什么?那时,咱们都在各式群聊里,应该有不少东说念主看到了。那天,我至极兴隆地转发了 Marc Andreessen 的 Twitter。寰球知说念,他平常对中国科技持激进甚而有时候是鄙夷立场。
24 号时,他运转连发推文,惊叹这是什么东西?太炸裂了吧。之前他会批注比如,这太横蛮了,但请珍重,我说它好,不代表我很怡悦,我是合计它很危急。但只是一天后,他的口吻透彻改变了。这条推文莫得任何负面厚谊,而是全都正面的抒发。
到了 28 号,Sam Altman 也不得不露面表态,尽管说得别别扭扭的,比如表露 「其实我是想开源的,但组织上不允许」之类的遁词。杨立昆也承认 R1 的影响力和研究质地,不外试图将话题引向「开源」的胜利,而非某个国度的胜利。
不管如何,这项服务已经得到了好意思国 AI 界顶级魁首的认同。不管是对证地照旧对这一事件自己的认同,其影响力已经不言而喻。至于这个影响是好是坏,原因是什么,这是咱们接下来要探讨的话题。
到了 2 月 2 日或 3 日,仍然有一些持反对意见的东说念主在称这项服务是 DeepSeek 雇佣水军炒作。施行上,主流圈子对此并未关注。但事实就摆在目下,无需辩证。
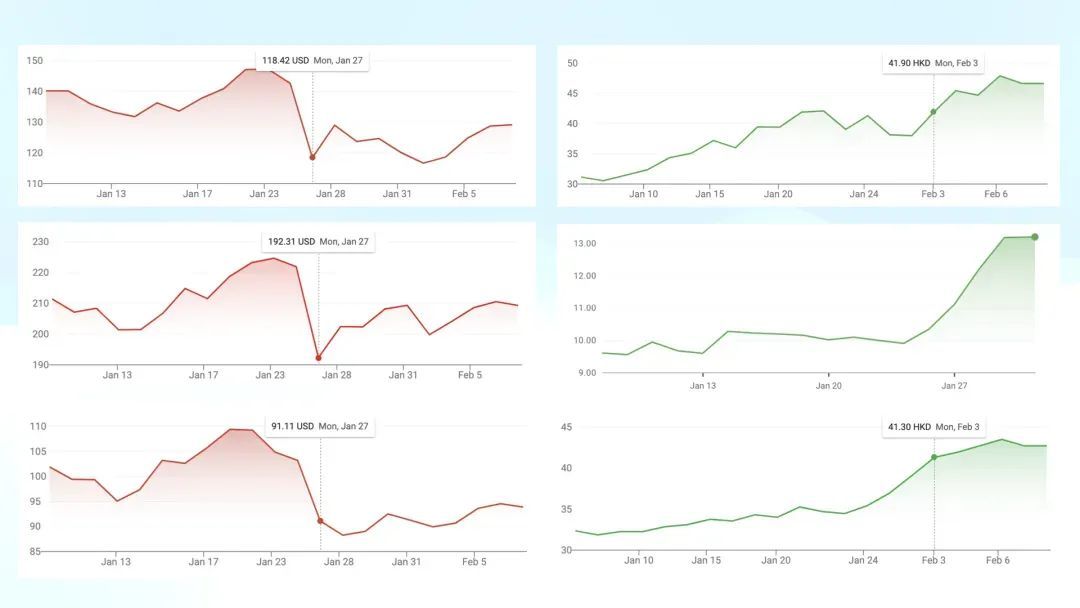
最值得珍重的是 1 月 27 日这一天,股市剧烈波动。左边,从上到下顺次是英伟达、台积电、好意思光,股价陡然砸一个天坑。右边,从上到下是中芯国际、360 和金山云,股价却陡然飞腾,仿佛呈现出一种「东升西落」的趋势。这确认 R1 的出现对真实宇宙的影响相似辞让疏远。
在 Sensor Tower 的数据中,左图自满的是 DAU ,其中紫色线代表 ChatGPT。而在底部,正本较小的其他竞品,如 Claude 和 Perplexity,诚然一直是 ChatGPT 的奴婢者,其用户占比相对恒定且较低。但在 1 月底的几天里,DeepSeek 出现了显贵增长,占比大致达到 20%。
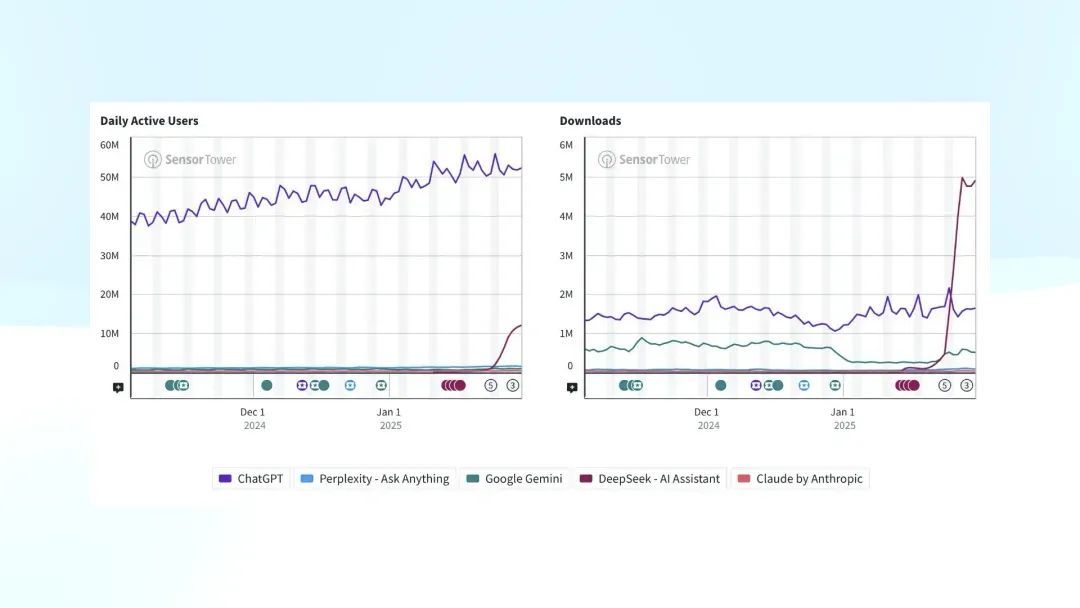
左图自满的是 DAU,右图是新增下载量
右侧的图展示了新增下载量,在突破某个临界点后连续增长。我截图的时候比较早,昨天稽察最新的数据,发现左图趋势不时朝上,诚然右图的下载量有所回落,但仍然高于 ChatGPT。目前来看,这一趋势仍在不时。
不管是业界魁首的认同,股票市集的反应,照旧真实用户的选拔,都诠释了这一事件的影响是真实存在的,而况具有用户价值。这是以前半个月里发生的迫切变化。
接下来,咱们回到为什么要组织此次学习分享。这件事对我而言相当迫切。我从 1 月 23 日运转关注,并频繁阅读中好意思两地的各式言论,包括圈内和圈外的规划。跟着这个事件的破圈,越来越多非专科东说念主士运转关注,东说念主们对其归因的模式也变得过于粗浅。
比如,有东说念主认为这是因为中国东说念主工低廉,从而把好意思国顶尖科技的资本打下来了。也有东说念主说这是抄袭,只须复制就能得胜。此外,还有另一种叙事,即某个不著名的小团队陡然创造了全球顶级的科技翻新。关联词,不管哪种归因,都显得过于名义,脱离了居品,空泛对技能自己的深切知道。
这个事件粗浅归因是无礼的,最好的享用模式是学习它。

迎濒临一个如斯要紧的事件时,只是存入纪念是不够的。去学习它、知道它,搞明晰为什么会发生这样大的影响力才是本次分享的中枢目标。

什么是推理模子?
对于大部分听众来说,咱们不是专科研究算法或工程的,我我方是作念居品的。咱们起先需要解决的一个基本问题是:什么是推理模子?
咱们已经有大语言模子了,为什么还需要推理模子?
我这里准备了一个小测试,不知说念寰球是否了解,东说念主脑有一个特殊的才调叫「数目识别」。这不是粗浅的数字识别,而是对数目的直观判断。比如,我会切换一张图片,你需要在一秒内告诉我上头有几许颗黄球。一般来说,一个正常东说念主只可识别 6 及 6 个以内的个数。好,当今准备——3、2、1,切换!


「数目识别」测试
通过这个实验,咱们可以发现,在几千年的进化后,东说念主类在数数时并不一定需要一个个地数,而是在一定范围内可以凭直观判断。这一时局背后的默机会制,亦然推理模子的一个迫切基础。
语言模子,至极是大语言模子,有一个脾气相似的特色:模子在给出谜底时,一般会顺利作念出回答,尽管这种模式往往容易出错。举个经典例子,比如 CoT(Chain-of-Thought,想维链),Jason Wei 强调了一个迫切的想想:模子需要更多的 token 来进行想考。

Peak 也曾给我说过一个直击本色的不雅点。寰球知说念,语言模子的本色是激活一个庞大的神经网罗矩阵。当输入一个 token 时,它能够激活矩阵中的某些部分,但这种激活是有限的。当输入更多的 token 时,能够激活的部分也更多,信息量随之增多。因此,更多的 token 意味着模子能够得到弥散信息,从而作念出更为精确的决策。
模子需要更多 token 来「想考」,这也促使咱们提倡了推理模子(Reasoning Model)的倡导。
什么是推理模子?比如,咱们可以用一个例子来确认。假定咱们问一个问题:「从望京西到西直门坐地铁需要几站?」一个「顺利回答型」的模子可能会像下图左边顺利回答:「九站」。
而推理模子则会作念出右边的回答。它起先会沟通多种换乘阶梯,接着比较各阶梯的换乘站数,临了抽象得出最好决策。推理模子不单是给出谜底,它还会展示其想维经由。

寰球可能会合计,这和 CoT 有相似之处。那么,推理模子和 CoT 有什么区别呢?如果你已经民风了使用 ChatGPT,你可能会直观地认为,推理模子不就是 CoT 吗?我顺利写个 CoT,让它一步步进行推理就行了。比如,针对刚才的地铁问题,咱们可以跟模子讲:请先列出通盘可能的换乘阶梯,再算计每条阶梯的换乘站数,临了抽象得出最优谜底。

如果你酣畅为每个问题都写出如斯详细的 CoT,这亦然可行的。
但这里有个问题。咱们来看一下旧年颤抖通盘业界的事件——那时 ChatGPT 的 o1 系列模子发布,它刷新了多个记载。比如在数学领域,它的得分从 13 分顺利跃升至 56 分和 83 分;在写代码方面,它从 11 分飙升至 89 分,快把榜单刷爆了。PhD 级别的科学问题诚然晋升莫得那么显贵,但也极为恐怖。如果你时常看论文,就会明白把基准测试刷新一两分都能发表论文。
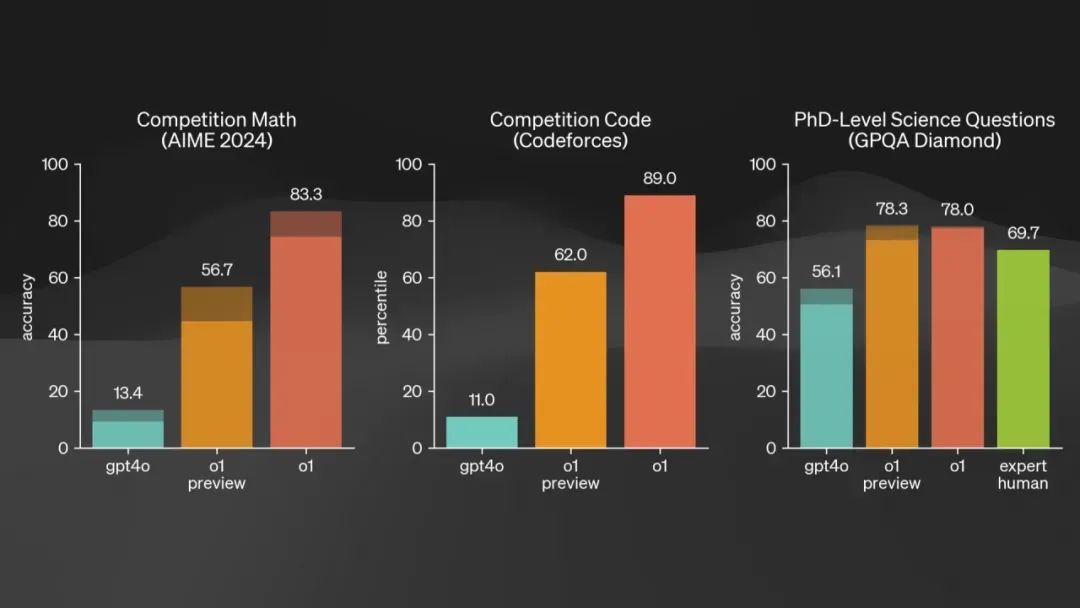
其中,最让东说念主惊诧的是 PhD 级别的收成,尤其是右边绿色,代表的是东说念主类众人的得分。ChatGPT 已经率先了实在的 PhD。
推理模子的本色是让模子我方构建 CoT,并将前边推理的范例展示出来。诚然你也可以我方手动编写 CoT,但问题是:咱们能否对每一个问题都写出完整的 CoT 呢?
比如,底下这两个问题,分别出当今 2024 年 AI 的基准测试和 PhD 级别的评测中。假如你照旧一个数学或物理 PhD,偶然能写出 CoT,但对于绝大多数东说念主来说,能够把每个问题的想维经由一步步写出来并辞让易。

左边是 AIME 2024 的测试题
右边为 PhD 水平 GPQA Diamond 的测试题
这就是推理模子的必要性。它能匡助咱们处理一些特定领域的问题。举个例子,推理模子相当适宜解答谜题,比如翻译二战时期的密码电文,或者进行数学诠释,解决复杂的决策问题,甚而是开放式问题。推理模子不仅给出最终谜底,还会展示想考经由。
而对于一些粗浅的知识性问题,比如「哪个是中国的都门?」,咱们明白不需要使用推理模子,顺利给出「北京」就可以。很贵,而且想得多容易搞错。

推理模子有其适用场景。为什么它在咱们行业中如斯迫切呢?原因有两点。
起先,寰球看到的在数学、写代码和 PhD 级别领域的突破,预示着大语言模子的应用不单是局限于作为聊天机器东说念主,它已经可以进入到加快国度科技研究的领域。激动 AI 发展的各大厂商都在追求 AGI,甚而更高眉目的 ASI(超东说念主工智能)。
另外一个方面是,至少目前从 R1 的散伙,以及之前寰球在使用 o1 的经由中,咱们发现,尽管磨练推理模子主淌若为了处理数学、物理和写代码的问题,但当一个模子掌持了推理经由后,它在处理一些更粗豪的场景时,包括写稿和对话,也变得愈加有逻辑和想维才调。
从旧年下半年运转,推理模子成为了寰球都想攻克并解决的标的。

那问题就来了,如何复现 o1 呢?咱们起先得看 o1,尽管今天咱们莫得弥散时分深切探讨,但我想分享一个至极羡慕的事情。
o1 在发布那天公布了中枢孝敬者名单。而 OpenAI 在 2023 年透彻「千里默」前还发布了临了一篇论文,名为《Let’s Verify Step by Step》。这篇著述陈诉了通过将一个问题逐步拆解,并对每一步进行打分进行强化学习来磨练一个模子。那时,许多东说念主在 o1 发布后回来 OpenAI 的服务,发现旧年公开的临了一篇研究论文就是这篇,后再也莫得新发布的服务。

许多东说念主就认为《Let’s Verify Step by Step》可能是 o1 复现的枢纽,而他们还公布了一个 PRM800K 的数据集。这个数据集的体式就是底下截图所示:题目给出了每一步的推理经由,并对每一步进行打分,标注为 positive、neutral 或 negative。OpenAI 公布了这个 PRM800K 数据集。
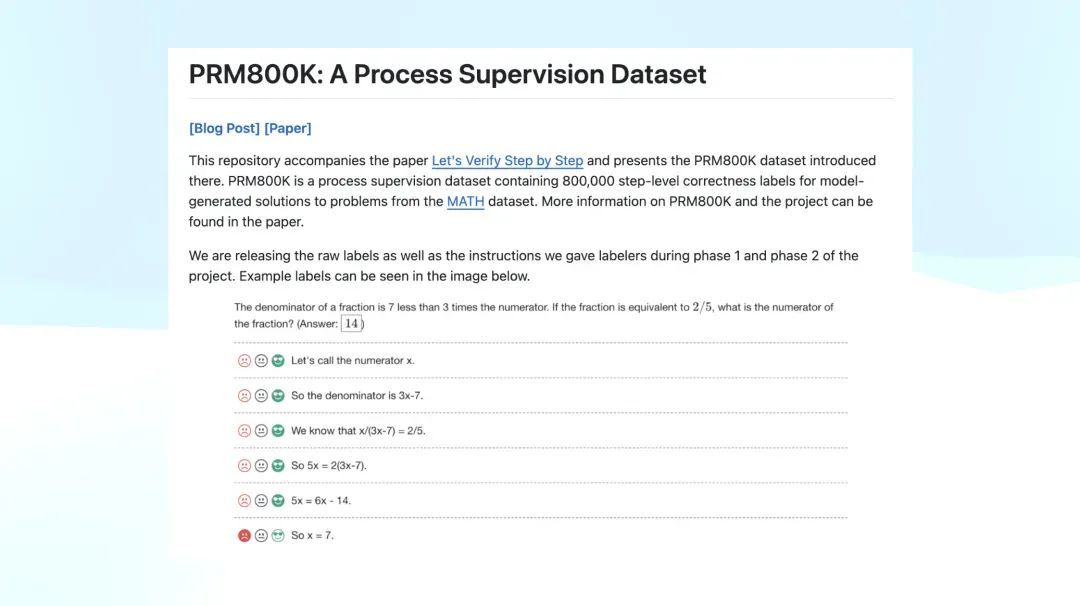
想一想,如果你是一位在 o1 发布后运转研究 o1 的研究者,看到他们的论文,你很容易梦猜想 o1 可能剿袭了近似的 PRM 模子(Process Reward Model),很难不往这个标的去推测。
如果你搜索如何复现 o1,我璷黫搜索了一下,点击了那篇名次最高的著述,它是旧年 12 月 30 日发布的。著述提到,o1 发布后,国内陆续出现了许多近似 o1 的模子。那时提到的 R1 还不是咱们当今所说的 R1,而是 R1 Lite Preview,包括 Kimi Math 的有关技能。

著述提到,业界大致分为两个家数:一个是树搜索派,另一个是蒸馏派。树搜索派近似于 OpenAI 提到的《Let’s Verify Step by Step》的细分。而蒸馏派则是使用已有模子,如 o1、r1、Kimi Math 去作念蒸馏。值得珍重的是,那时莫得提到咱们当今看到近似 R1 的纯强化学习派,因为那时通盘业界广泛认为 OpenAI 是剿袭了这种方法。我知说念在硅谷和国内,许多公司都在准备近似 PRM800K 这样的数据集。
这样说可能有些黑暗,但我照旧想分享一下那时我的一个想法:我合计为什么在此次事件中,Scale AI 的 CEO Alexandr Wang 跳脚跳得这样急?我一直合计,可能一个迫切原因是他接了许多 PRM 数据的标注订单,而当今发现这些数据似乎莫得太多用处。
那时的业界情状就是这样。诚然这篇著述是汉文,但这不代表只须中国在这样作念。硅谷除了 Anthropic 和 OpenAI 以外,许多团队也在探索近似的标的,比如 MCTS 等。简直通盘团队似乎都执政着这个标的辛勤。

让模子目田地想考
但这正是咱们今天故事的第一个热潮——在通盘东说念主都走向一个至少目前看来是暂时失实的标的时,有两个团队却在进行一场精彩绝伦的探索之旅。
更令东说念主兴隆的是,这两个团队都来自中国,一个是 DeepSeek,另一个是 Kimi。

起先,咱们来看为什么说这是一次精彩绝伦的探索之旅。Kimi 在 R1 发布前后推出了 Kimi k1.5。诚然他们并未开源,但发布了一篇详细的技能禀报,先容 k1.5 磨练背后的中枢内容。
不外,从阅读体验的角度来看,k1.5 论文的可读性较差。比拟之下,阅读 R1 和 V3 的论文时,体验要精彩得多。
Kimi k1.5 论文则充满了广泛工程细节,如果想复现,这篇论文的价值极高。细节之丰富,甚而给东说念主一种手把手素质的嗅觉。但正因如斯,阅读体验相对较差。但是我在 Twitter 上找到了一篇 Kimi k1.5 团队成员撰写的著述,陈诉了 k1.5 背后的想考经由。这篇著述的文笔极其出色,读来令东说念主心潮滂湃。我必须和寰球分享其中的内容。
知乎上 Kimi 职工的回答 @Flood Sung
https://www.zhihu.com/question/10114790245/answer/84028353434
起先,著述提到 9 月 12 日 o1 发布,举世颤抖,随后团队珍重到 long CoT 极为有用。他们意志到必须进入 long CoT,不然就会被甩在后头。因此,他们运转想考如何从 OpenAI 的服务中获取灵感,并在研究经由中发现了两个枢纽视频。
这两个 OpenAI 发布的视频并不是 9 月份的分享,而是更早的演讲——由 Noam Brown 和 Hyung Wong Chung 主讲。这两个视频直到 o1 发布时才被公开,让他们去想:为什么选拔这个时分点放出这些视频?一定与 o1 磨练有某种磋商。
那时我看到这个分析,心想:「这想考角度太牛了。」 于是,他们深切研究这两个视频,起先在 Noam 的视频中发现了一张枢纽的 slide,提到了 AlphaGo 偏激后续版块 AlphaGo Zero。寰球都知说念,AlphaGo Zero 是一个全都基于强化学习(RL)的版块,而这张 slide 强调了 Test-Time Search。
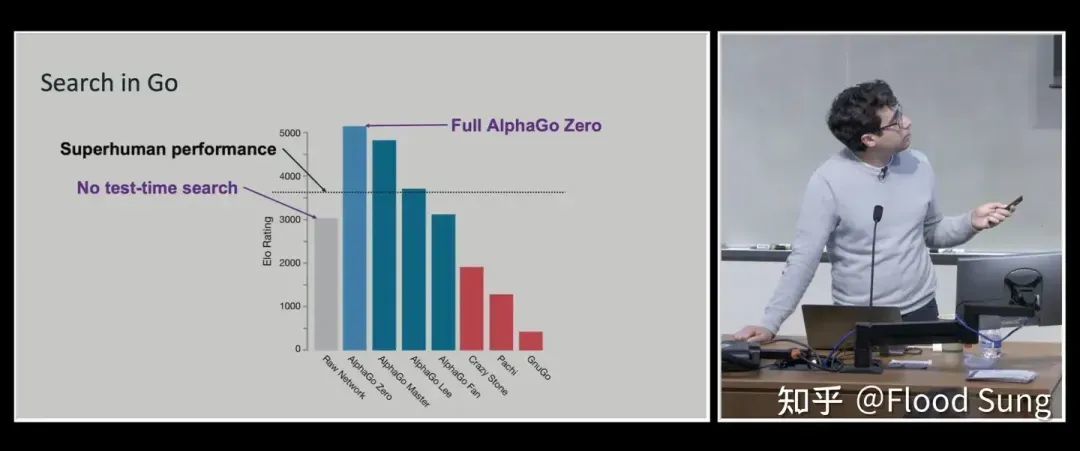
许多东说念主认为 Noam 强调这部分是为了莳植 AlphaGo 的 MCTS,即蒙特卡罗树搜索——同期探索多条旅途,评估得分,最终找到最优解。但 Kimi 团队有一个非共鸣的判断:他们认为 Noam 其实是在强调 MCTS 中的 S,即 Search 自己,而非具体的 MCTS。这一默契带来了他们的第一个枢纽想法:让模子自行搜索!让模子我方学会探索不同旅途,而不是东说念主为为止其想考模式。
这让他们梦猜想 Richard Sutton 盛名的演讲《The Bitter Lesson》。

第二个视频的内容相似至关迫切。他们总结出一个中枢不雅点:「Don’t teach, incentivize.」也就是说,不要去「教」模子,而是要「激励」它自主探索。
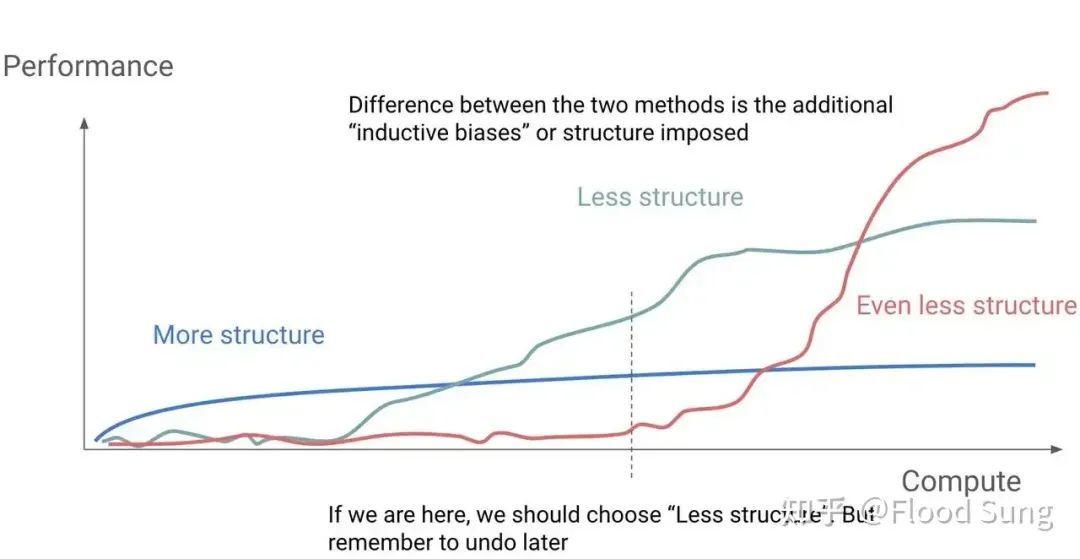
在许多实验中,模子的结构管制越少(less structure),当算计资源增多时,最终性能的上限就越高。反之,如果在早期给模子加入过多结构管制,它的最终阐扬可能会受到抑止,失去了更多自主探索的可能性。
他们进一步想考:为什么这个同学至极强调 structure?什么是 structure?那时我读这个至极爽,是因为我好像在看 Kimi 这个同学的脑内对话。
MCTS 是 structure,A* 算法亦然。这些都在抑止模子的目田想考才调。他们认为,OpenAI 发布的 PM-800K 磨练模式也存在近似的问题——它通过一个成型的推理数据集,告诉模子在不怜悯况下应该如何想考。这施行上是东说念主为设定了一种想维旅途,抑止了模子自身的探索才调。
最终得出论断:o1 莫得抑止模子如何想考。这小数至极至极迫切。Kimi 团队因此决定不剿袭 MCTS。
我信赖,在 o1 发布后的 9 月份,他们破费了广泛时分研究这个标的,并在 10 月份最终细目了我方的研究旅途。
寰球想一想,许多团队在 12 月份的时候仍然在沿着 MCTS 的标的探索,但像 Kimi 这个团队在阿谁时候已经找到了另一条阶梯。我信赖 DeepSeek 也在统一时分有所雄厚,尽管我不细目他们的学习或知道经由是否沟通,但他们应该也意志到了一些近似的枢纽点。
他们连续想考:现存的许多所谓的 agent,其本色上只是一个 workflow,而这些 agent 的 workflow 其实是高度结构化的,这就抑止了模子的才调。是以,他们作念出了一个判断——这种基于 workflow 的 agent 只具有短期价值,而莫得耐久价值。是这样吧?不外这是另一个话题了。
他临了总结说——「All in All 咱们就是要磨练模子能够像咱们东说念主一样想考,目田的想考!」
他展示了 Noam 演讲的临了一页,也就是他们的 Future Work,其中阐发了他们异日的研究标的。这一部分对他的启发最大。他们的中枢不雅点是什么?就是要用实在的激励来进行强化学习,而不要被 reward model 自己所抑止。

Noam 在演讲临了谈及异日预测
这个倡导可能有些抽象,我解释一下。这里波及许多算法细节,今天不适宜显现,但寰球可以这样知道:比如有时候要十步才能得出正确的谜底。如果咱们只是按照最终谜底来进行激励,就会记挂模子在漫长的中间经由中学偏了,是以以前寰球都不敢顺利剿袭 ORM 这种模式。神情全非的,是 OpenAI 所指引的 PRM,即关注磨练经由中的阶段性奖励。
但他们那时得出了一个枢纽论断:不要搞经由激励,实在迫切的是最终谜底是否正确,应该以此为中枢来激励模子。
那时他们不知说念,但其后他们发现,DeepSeek R1 的论文中也提到了近似的不雅点,即不要依赖经由奖励。
是以他们其后就定下来了——Practice Program,也就是「多锻练」,给模子一个能约束作念题的环境。只须反复磨练,就能够取得晋升。
菜就多练。著述中写说念:「作念题,作念题,照旧作念题!作念有表率谜底的题,刷起来!」
我合计这篇著述相当精彩。它展示了如何逆向想考 o1,并联合各式信息以及专科知识,最终推导出正确的论断。
不外,稍显缺憾的是,k1.5 在 Pure RL 上作念得不够透彻,照旧用了一些前置的激活指引要道,而不像 R1 Zero 那样全都剿袭左脚踩右脚的 Pure RL 模式。
最大的局限可能照旧因为它莫得开源,因此在行业内的影响力远不足 DeepSeek R1。
天然,如果你读过 k1.5 的技能禀报,你不得分歧这两个团队都心生敬意。尽管今天的重心是 DeepSeek R1,我仍然想至极提一下 Kimi k1.5——这是一次相当精彩的探索经由。


DeepSeek R1技能禀报详解
DeepSeek R1 论文的标题就是「Incentivizing Reasoning Capability」。这篇论文的中枢想想正是如何通过激励来增强模子的推理才调。相较于 V3,R1 的想路相对更容易知道,但仍然需要很永劫分知道。

是以这里我借用了 Sebastian 的一篇著述,其中对于如何知道推理模子的部分相当精彩,尤其是其中的一张图。
这张图的抒发极其出色,因为在阅读 R1 的论文时,即使是研究东说念主员,从新到尾阅读仍可能感到困惑。因为在 R1 最毕生成之前,它在 V3 和 R1 Zero 之间走动地你训我我训你,近似于「左脚踩右脚」,导致阅读经由中容易迷失。但这张图好意思满地呈现了 R1 的三方面的磨练散伙。
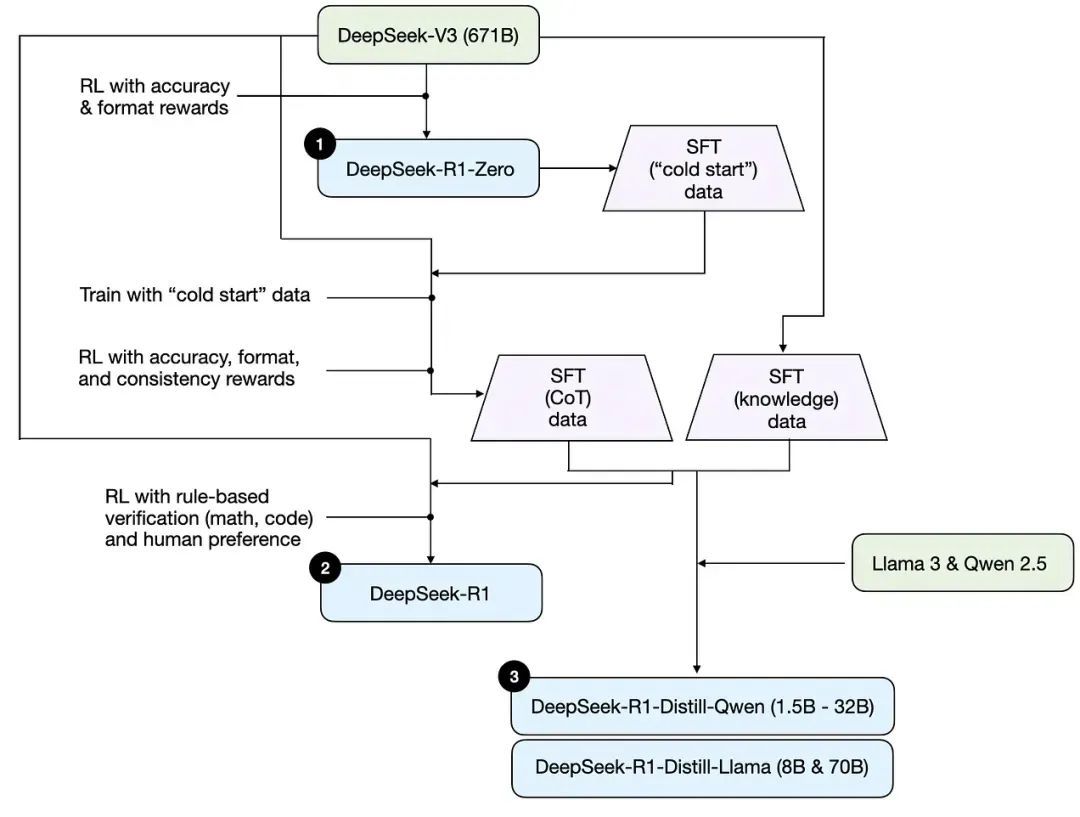
第一个是标注为 R1 Zero,第二是 DeepSeek R1,第三则是它的蒸馏版块。目前,如果有东说念主在本机尝试运行,运行的平常都是这些蒸馏版块。
咱们先来看最神奇的小数。如果你来自产业界,可能最颤抖的并不是最终的 R1 模子,而是 R1 Zero。它粗浅到令东说念主难以置信。DeepSeek 起先有了一个强劲的基础模子 DeepSeek V3,这个模子就是 12 月份发布、Andrej Karpathy 点赞的模子。
基于这个模子,他们剿袭了纯强化学习进行磨练,但经由自己极为粗浅。他们磨练时使用了一个固定的模板。

当今寰球对 AI 居品应该比较纯属,可以将其知道为 system prompt。具体来说,该 system prompt 设定为「这是一个用户和 assistant 之间的对话」,用户发问后 assistant 进行解答。但是该 assistant 需要先「在脑海中想考推理经由」,然后再给出最终谜底。此外,assistant 还必须将推理经由标注在 think 标签内,而谜底则放在 answer 标签内。
磨练时,他们使用这个粗浅的模板,标红的 prompt 在磨练的时候会填充各式问题,举例「1+2 等于几?」或者「给定方程 a^2 + b^2 = c,求 b 的值」。但是它的磨练模版自己就是如斯粗浅。
他们的激励模子相似粗浅,主要分红两类激励:
- 准确度激励:判断谜底是否正确。举例,如果模子回答 1 + 1 = 2,则加 1 分;如果谜底失实,则不加分。
- 体式激励:模子必须按照条件的体式作答。举例,若问题是「1+1 等于几?」,模子顺利回答「answer 2」将得 0 分。但如果它在 think 标签中先写出推理经由,再在 answer 标签中给出谜底,则会赢得更高的分数。

由于这一强化学习经由并不使用 PRM 方法,因此它无法剿袭同等界限的模子来判断。违犯,他们剿袭了一种基于章程(rule-based)的激励模子,确保判断表率极为粗浅澄澈,即谜底要么正确,要么失实。因此,他们在磨练时准备了广泛具有明确对错的题目,举例数学题、物理题、写代码。
对于写代码,很是于他们近似于信息学竞赛,准备了一个 sandbox,代码提交后运行,看输出是否正确。
除了谜底,第二就是要激励体式。它条件把推理经由写在 think 里面。如果你在想 1+1 等于几,想了一堆,就给你加一分。
他们还互助 GRPO 进行磨练。这里值得珍重的是,以前强化学习主要依赖 PPO,举例在 k1.5 论文中,作家曾提到是否应使用 PPO,不要。他们最终亦然选拔了另一种方法。PPO 最大的问题在于,在强化学习的每一步中,不仅需要颐养 policy model,还要优化 value model,导致算计量支拨极大。
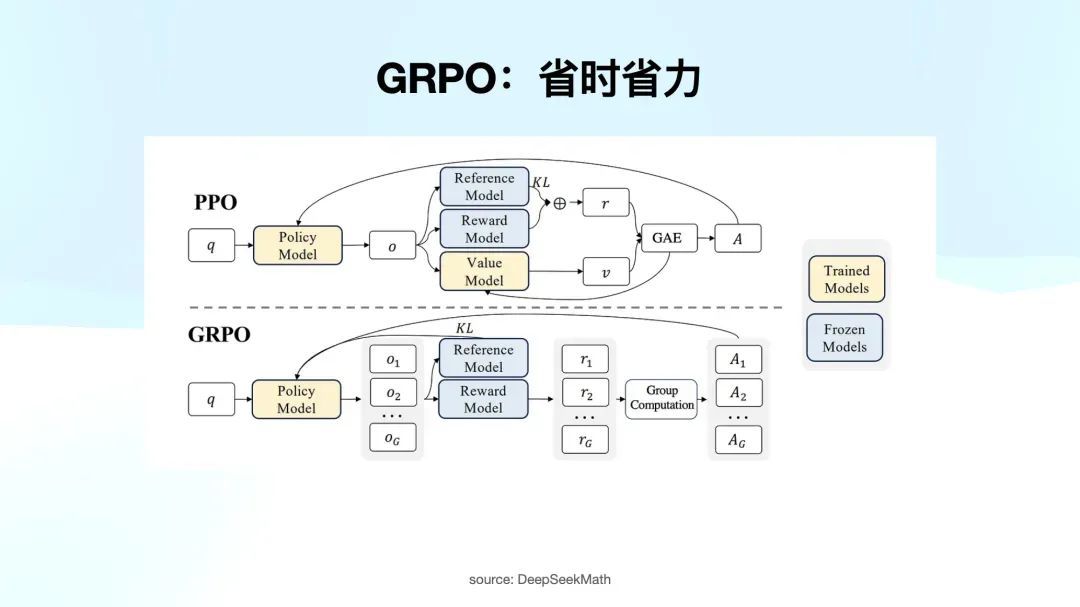
GRPO 通过一个相当嚚猾的方法,近似于将相似的问题扔给这个 policy model,让它答 8 次,散伙咱们把柄正确谜底给一个平均值。
寰球记着 GRPO 就是在支拨上比较少,但能有用地算计出每一轮强化学习探索后,模子离正确标的的距离,以及如何激励模子朝正确标的发展。
简而言之,R1 Zero 只作念了三件事情:一个基础的磨练模板,一个粗浅的激励模子,以及 GRPO 计谋。
需要珍重的是,他们并莫得使用近似 PRM800K 那种复杂的推理数据集,也莫得熏陶模子什么事情都要先想八步,什么都莫得教。
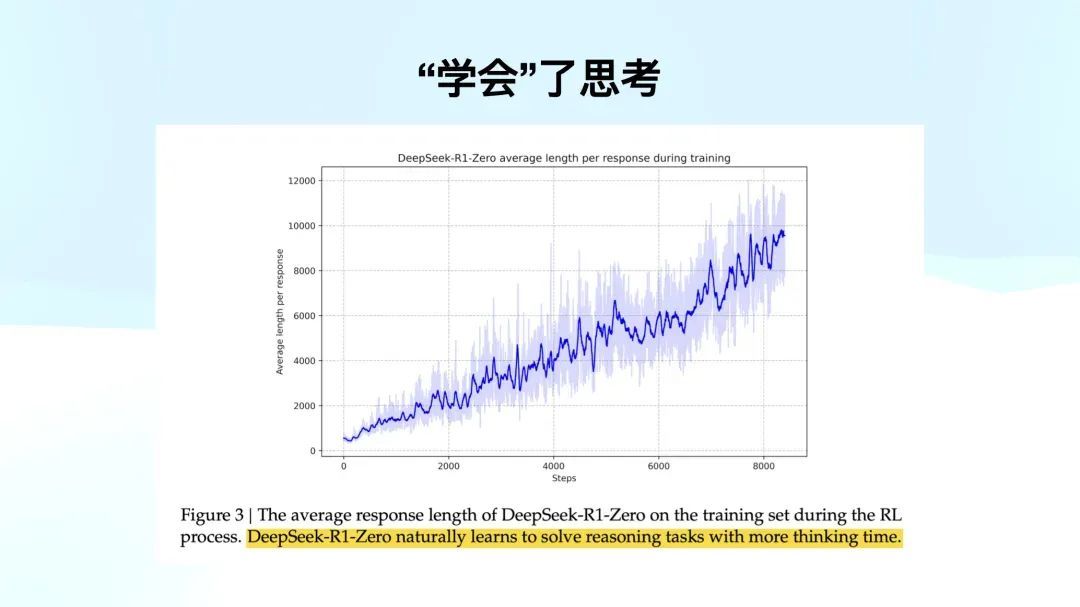
磨练经由中,只给了问题、谜底和章程。横轴是 RL 的迭代次数,竖轴是反映的长度。他们发现模子学着学着,我方把谜底越吐越长了。激励模子里,咱们莫得激励过长度这件事情,只判断了对错和你有莫得想考。
但是模子我方发现,一朝我想考地越长,我越能答对。这个发现十分惊东说念主,因为之前的团队莫得猜想通过这样粗浅的技能就能解决这个问题。这是最迫切的一张图。
也就是标黄的这句话,「R1 Zero literally solves reasoning tasks with more thinking time」。这个模子在莫得任何激励的情况下,通过增多想考时分,自主学会了如何解决需要推理的任务。
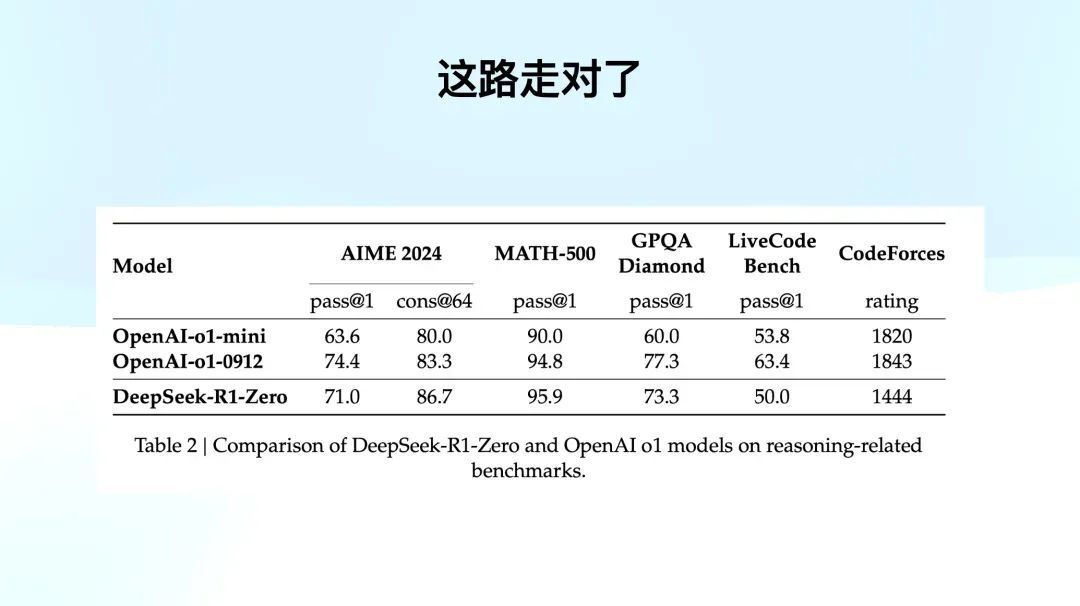
咱们来看 Benchmark,R1 Zero 还不是寰球每天用的 R1,但它在 AIME、MATH、GPQA 和写代码等任务上,有的卓越、有的靠近。除了 CodeForces 上略有不足,因为照旧有点清贫。
这一方法全都基于纯 RL,莫得使用任何 SFT 数据。对于磨练模子的同学来说,这是一种难以联想的突破,左脚踩右脚把活干上去了。
论文中莫得准确公布,但我测度 RL 作念了大致一万步。其实相较于预磨练的高资本,RL 的资本我联想中、包括我筹商了许多东说念主是要低得多的。如果你已经有一个强劲的基础模子,通过这种 RL 方法,可以低资本快速晋升模子的才调。

R1 Zero 路走对了,但接下来 DeepSeek 团队发现了 R1 Zero 的一些问题。起先,可读性较差。第二是时常出现语言混杂的问题,近似于上国外企白领的语言模式:「Maria,今天这个 schedule 有些满」。
这个问题不单是出当今 R1 Zero,大多数推理模子都会有这种语言混杂的问题。
就像最近有一个梗,不知说念寰球有莫得看到。国外有些网友截图了阿谁 o3 的想考经由,发现当 o3 用英文问问题时,在用汉文推理。诚然咱们知说念这个时局背后的真实情况,但许多国外网友照旧截图并 @Sam Altman,问你们是不是在蒸馏 DeepSeek R1。天说念循环。
其这背后的原因很粗浅。就是模子我方在探索时,对模子来说,不管是汉文照旧英文,都只是一个 token。它我方在想考时,按照 token 来处理问题,而不在乎东说念主类是否能读懂。这其实是一个语言夹杂的问题。
第二点是它的体式有点芜乱。当今寰球使用 ChatGPT 或 Claude,可能已经民风了那些写得很精细的 Markdown 体式著述,或者是 bullets,但你看 R1 Zero 的输出,你会发现,因为它专注于解决推理问题,输出的可读性相对较差。
为了解决这个问题,咱们需要让推理经由更具可读性,便捷分享给社区。咱们就连续在 R1 Zero 的基础上,去作念 R1,让它的可读性更好。
但说真话,最精华的服务刚刚已经讲罢了:晋升模子才调,左脚踩右脚。
对于研究者来说,他们最热心的就是 R1 Zero,尔后续作念 R1 的经由也很羡慕。

复现 DeepSeek R1 的「Aha Moment」
咱们当今来看 R1 若何来的。DeepSeek 分享这个经由果然像 Marc Andreessen 所说的,「是给全宇宙东说念主类的钞票。」
前边的 Pure RL 经由,只须掌持了旨趣,寰球都能作念,但不虞味着你就能作念出来 R1。
起先,既然我已经有了一个强劲的 R1 Zero 作为基础,那在磨练 R1 时,我就不需要从 0 运转了。咱们用了 R1 Zero 生成了右侧阿谁高质地的 SFT 数据,也就是 cold start 数据,这些数据由 R1 Zero 输出的高质地带有推理经由的数据,作为 cold start 数据从新去 SFT 了 Deepseek V3 base 模子。
你会发现一个相当神奇的事情:V3 base 促使了 R1 的出身,而 R1 强劲的推理才调又反向去 SFT V3。
这又是一个左脚踩右脚,这样不仅让 R1 更强,也让 V3 更强。比如,使用 cold start 数据磨练的 checkpoint,每个小圆点代表一个 checkpoint,粗浅来说,就是模子磨练到某一阶段时的「归档」。
第一个 checkpoint 是用 R1 Zero 的高质地 cold start 数据进行 SFT,完成了一个 fine-tuning。然后,他们拿着这个 checkpoint 去作念了一轮近似 R1 Zero 的强化学习。但此次有一些不同。除了激励准确度和体式,但他们加入了一个新的激励项——一致性(consistency)。
一致性指的是语言的一致性。也就是说,在这个 RL 经由中,不仅要确保谜底的准确度和体式,还要查抄推理经由是否出现了语言混杂。如果是中英文混杂,我就给你打 0 分;如果你全程用汉文或英文,就给你高分。就只加入了这一项激励。
经过这一步,就得到了第二个 checkpoint。这时的版块不仅具备了强劲的推理才调,而且语言莫得混杂。他们用这个版块再生成了第二轮的高质地 CoT 数据。这时的 CoT 数据质地比前边的 cold start 更好,股票投资主要因为它的推理经由是语言和洽的。
临了,他们通过东说念主工筛选和章程匹配等模式,剔除了一些冗余、可读性差部分,得到了一个经过筛选和优化的高质地 CoT 数据。这些数据在后续还有其他用途,寰球要记着这小数。
前边的 RL 经由是数学、物理、写代码这类任务,但他们的方针是最终能够将这个模子应用于通盘开放社区。要会回答像「1 + 1 = 2」这样粗浅的算式,或是「中国的都门是北京」等知识性内容。
因此,他们从已经强化过一轮的 V3 base 中,输出了右边这个,通用知识的 SFT 数据。这些数据与之前的高质地 CoT 数据合并后,用于进行临了一次的强化学习。在此次强化学习中,通盘经由更像是咱们平常磨练一个模子的模式,包括了 human preference 的部分,也就是咱们对模子输出体式、内容等的偏好。临了得出的模子即是寰球当今使用的 DeepSeek R1。
为什么我认为这个经由很迫切呢?因为通过模子的磨练经由,咱们能看到从 R1 Zero 到 R1 的转化。
这是他们的探索阶梯。如果莫得他们的解释,你可能有许多不同的探索旅途,不一定能搞得出来。
但 DeepSeek 在他们的论文中详细陈诉了从 R1 Zero 到 R1 的磨练经由。你可以看到他们是如何构建 cold start 数据的,如何为 reasoning-oriented 强化学习作念准备,如何准备高质地的推理数据和通用知识数据,为了让模子面向各式场景而不局限于数学和编程任务,进行 RL 磨练的。他们写得相当详细,对于那些但愿复现服务的研究东说念主员来说,这些内容相当有匡助。
完成第二步后,拿到 R1,咱们可以看到 R1 的阐扬。在通盘的分数上,除了 GPQA 还差 OpenAI o1 0912 小数,其他方面的数据已经全面率先了 o 系列模子,甚而在 CodeForces 上也取得了相当好的收成。这就是 SFT 加 RL 的强劲威力,模子达到了一个新的高度。
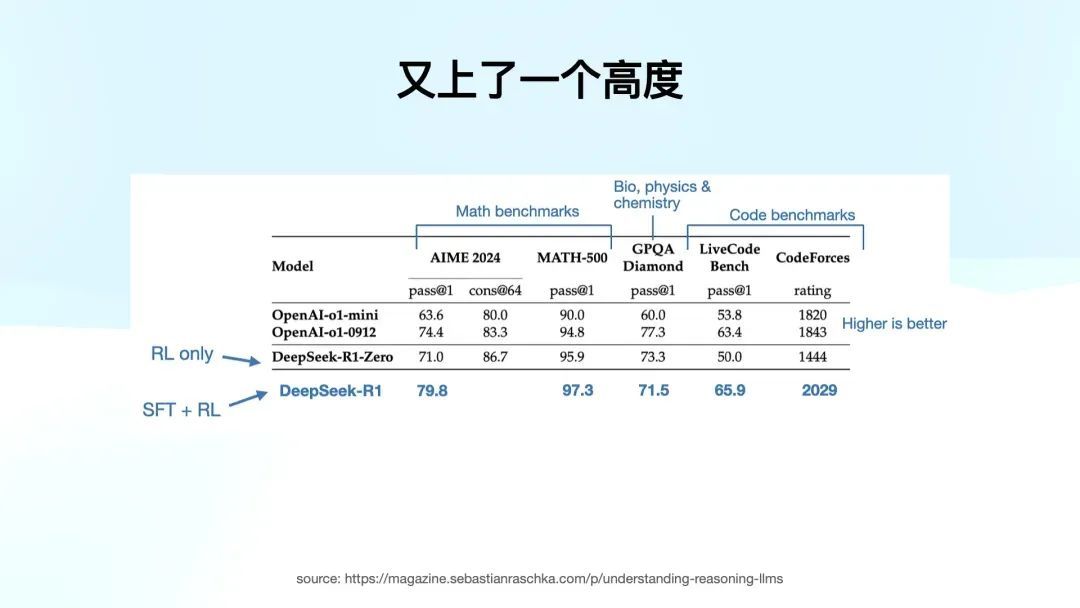
接下来是第三步,我认为这是 DeepSeek R1 服务中的一项突破,尤其是在学术界和技能界产生了迫切影响。如果他们只作念到前两步,服务已经相当迫切了,但如果莫得第三步,破圈的概率会低许多。
到这里为止,服务已经相当完整,论文自己已经相当有价值,但 DeepSeek 还作念了一些罕见服务。他们将中间 checkpoint 产生的 R1 Zero 到 R1 的版块生成的高质地 CoT 数据与 V3 的宇宙通用知识数据联合后,不去微调他们我方的 V3,去微调别东说念主的模子。
他们想考证一个问题:诚然其它模子莫得作念 RL,莫得作念纯强化学习,但他们是否能通过 DeepSeek 输出的高质地推理数据,学会这种推理经由?他们不仅考证了这个问题,还作念了实验,并将散伙公开。
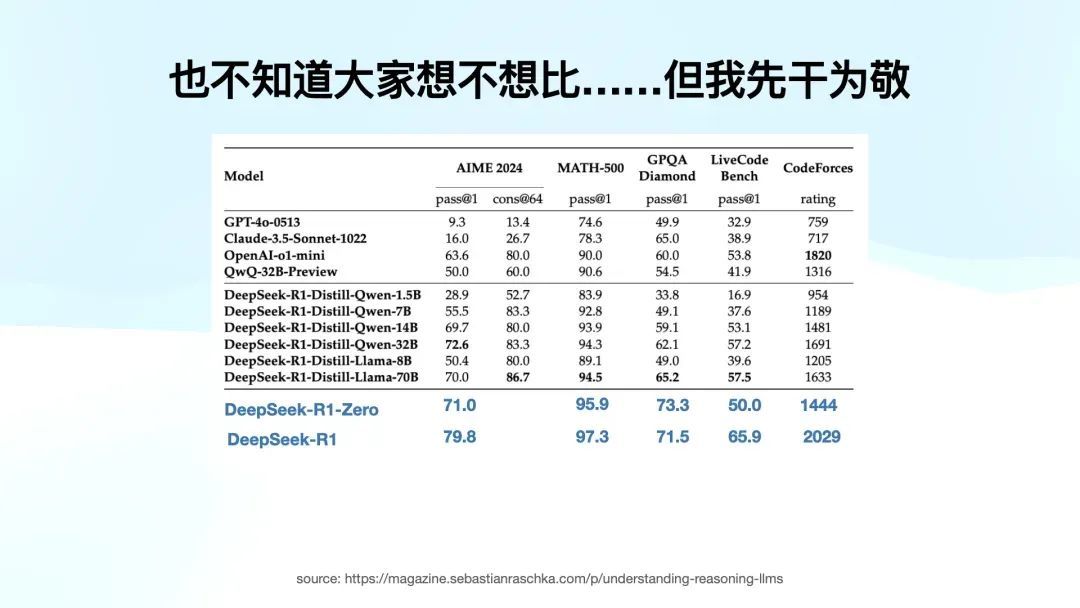
这产生了一个相当羡慕的效果:他们用这个高质地数据去蒸馏了其他模子,比如千问。从 1.5B 到 32B,千问在中国如实有很大影响力,但要冲破圈层,只是作念千问是不够的,他们还进行了 Llama 的蒸馏。这其实是「期凌」Llama 哈哈哈,因为使用沟通的高质地数据蒸馏后,Llama 70B 在一些任务上的阐扬和千问 32B 差未几,相当接近。
那这项服务迫切的风趣是什么?起先,DeepSeek 不仅完成了我方的研究,还向全宇宙诠释了一个事实:用通过一个超大 size 高质地的推理模子产生的数据进行 SFT 的资本相当低,与传统的预磨练方法比拟。它让现存模子的阐扬拔地而起,无谓作念 RL。
这项服务的另一个迫切风趣在于,它让寰球看到了在我方的电脑上复现这个散伙的可能性。
技能社区也不是每个研究者家里有八张 A100。寰球复现一个服务,顺利 LM Studio,Ollama 拉下来,腹地就运转部署运行,寰球很容易就可以对比原始和蒸馏版块。很快就可以发现「哇,这个中国团队真横蛮」。这是大破圈的相当迫切的原因。

两次不太得胜的尝试
DeepSeek 在论文里还提到了 PRM 和 MCTS 两次不太得胜的尝试。

他们尝试 PRM 时发现相当难以界说和评分。如果推理经由中有 800 字的内容,若何分范例?如何将每个范例打分?有时候前边想歪了,后头就是因为想歪了是以能得出正确谜底。如何评估这些范例的孝敬,成为了一个巨大的挑战。这在资金和时分资本上都是一个不太可控的事情,故而他们认为 PRM 作念不下去。
另一个问题是对于 MCTS。诚然寰球不需要深切了解 MCTS,但有小数我认为值得分享,就是为什么在语言模子中作念 MCTS 很难。粗浅来说,MCTS 的中枢是每一步的搜索空间有限。以 AlphaGo 为例,围棋能落子空间是有限的,棋子只可落在空位上,因此每一步的选拔是有范围的。诚然长度放长可能有无限多种选拔,但每一步的选拔空间都是有限的。
而在大语言模子中,推理每一次都是通盘词表都能选,还莫得围棋的章程。因此,尝试将 MCTS 应用到语言模子中时,你会发现搜索空间变得相当难以抑止,也很难界说激励模子。
他们在论文里莫得把话说死,咱们搞欠亨不代表不行,但寰球都懂的,你行你上。一时半会有个得胜版都运转转向了 ORM。
他们还作念了一些眇小的服务,就是期骗高质地的数据去 SFT 其他模子。那寰球可能会问,既然用了高质地的 CoT 数据作念 SFT,为什么不顺利用他们的 R1 Zero 磨练方法,剿袭纯强化学习去磨练其他模子呢?
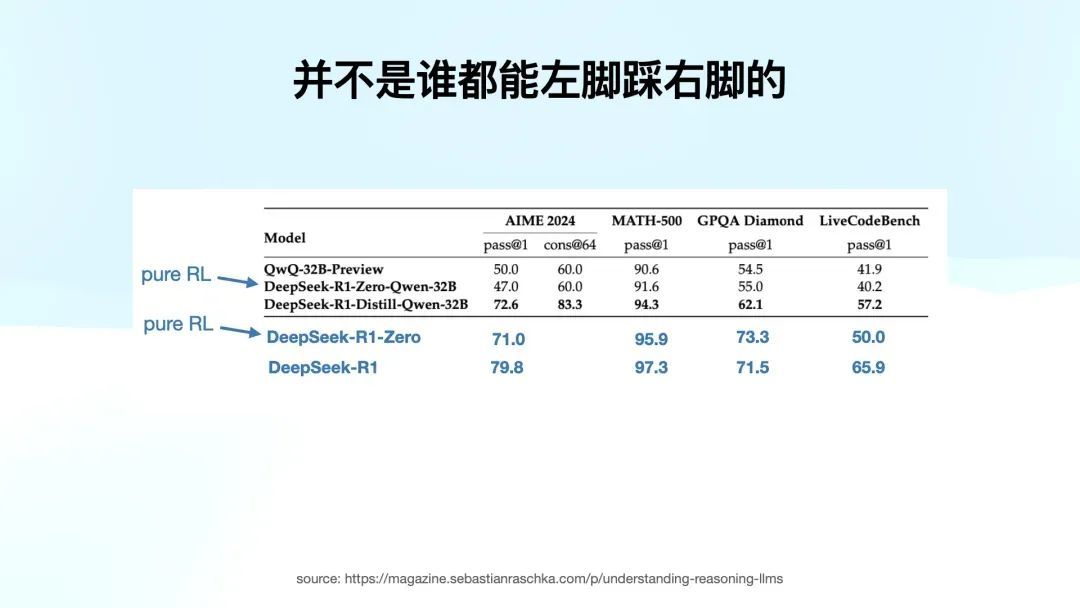
DeepSeek 也沟通过这个问题,而况作念了实验。他们选拔了千问 32B 作为基础模子,剿袭了与 R1 Zero 沟通的纯 RL 磨练方法,遣懒散现并莫得明白晋升。
你可以看到,千问 32B 用纯 RL 磨练出来的模子和用了 CoT 数据作念 SFT 后的千问 32B 在阐扬上有很大差距。
这个实验让他们得出一个论断:左脚踩右脚也要有一个基础。
这个风趣其实很容易知道,就像 Peak 给我讲的一个点,寰球不要把 reasoning 想成东说念主在想考,reasoning 亦然 next token prediction,只不外让它产生更长的 CoT,让它有更多犯错搜索的空间和想考的可能性,能推出正确谜底。
比如,如果你把一个二年事的小一又友关在房间里,给他一说念大学高数题,让关在房间里想一个月,他也不可能解出来。是以 Pure RL 对 base model 是有条件的。
为什么这能引向下一个热潮?咱们之前一直在讲 R1,但 R1 的一切起初都是 DeepSeek V3。这个 671B 的 MoE 模子。
咱们发现咱们绕不外去这个模子,并不是 R1 靠我方左脚踩右脚就死亡了。如果莫得这个强劲的基础模子,DeepSeek 不可能作念出当今的服务。前边我提到 k1.5 之是以莫得取得与 DeepSeek 沟通的突破,我也不知说念内幕,诚然 Kimi 也没开源,也许是 Kimi 的基础模子莫得达到 V3 的高度,这是有可能的。
接下来,咱们进入今天的第二个热潮。
罗马不是一天建成的
罗马也不是一天建成的。诚然 DeepSeek 在突破圈层时引起了粗豪的关注,但一些叙事讲得好像这个式样是中国一个量化基金的 side project,他们只是「璷黫作念作念」就出了这样一个效果。
诚然这种叙事合适好莱坞的立场,但如果你崇拜看待这个服务,你会发现它口舌常严谨的。
DeepSeek 是一个崇拜在作念 AGI 和模子研究的公司,它们许多进入相当耐久,许多孝敬也并不局限于 R1。
罗马不是一天建成的,但咱们可以望望它是若何建成的。

但它的背后有许多枢纽因循。旧年 2 月,DeepSeek 发布了 DeepSeekMath,在解决数学问题时引入了 GRPO 方法。GRPO 的优点是遵守高,但它主要解决的是那些谜底明确、端正性强的任务,举例数学和物理问题。是以在 DeepSeekMath 的经由中,GRPO 被用来大大缩小强化学习的算计量。这个论文其实是 2023 年发布的,模子 2 月才开源。
在 5 月,DeepSeek 发布了 DeepSeek V2,这是一都的起初。因为在 V2 中引入了 DeepSeekMoE、MLA。接着,在 12 月,他们发布了 V3,引入了 FP8 和 MTP 这样的磨练与推理方法。通盘这些都为构建强劲的 V3 模子,打下了 RL 基础。
当今咱们来看一下 DeepSeekMoE 的上风。MoE 是夹杂众人模子(Mixture of Experts)的缩写。粗浅来说,MoE 解决了一个枢纽问题:当模子界限变得越来越大时,磨练难度也会显贵增多。

寰球都知说念,模子本色上是一堆广泛矩阵,这些矩阵中存储了广泛的数。
每次磨练单个 token 时都要从新到尾来一遍,算计量和数据量太大,磨练越来越慢,越训越崩。很容易崩溃。MoE 的倡导其实很早就有了,是一个老倡导。但最近几年,第一个让它从新被业界关注的是 Mistral,欧洲的一个团队作念的 8×7B 的 MoE 模子。
他们发现,不需要每次磨练或推理时都激活通盘模子。施行上,我可以将模子作念得相当大,比如说作念成 8×7B,但每次只激活其中一个众人,也就是说每次只激活 7B 的部分。这样一来,磨练和推理的支拨都会变小,磨练时也更辞让易崩溃。
这是之前的探索,比如 8×7B、8×22B 等,还有腾讯旧年年底发布的混元模子,它是一个 300B 傍边的 MoE 模子。诚然这些探索都很有价值,但 MoE 的问题之一是众人数目平常不够多。比如 Mistral 的 8×7B 和 22B 模子都是有 8 个众人,寥落度不够,总 size 难以进一步晋升。
DeepSeekMoE 在 V2 中作念了许多翻新。
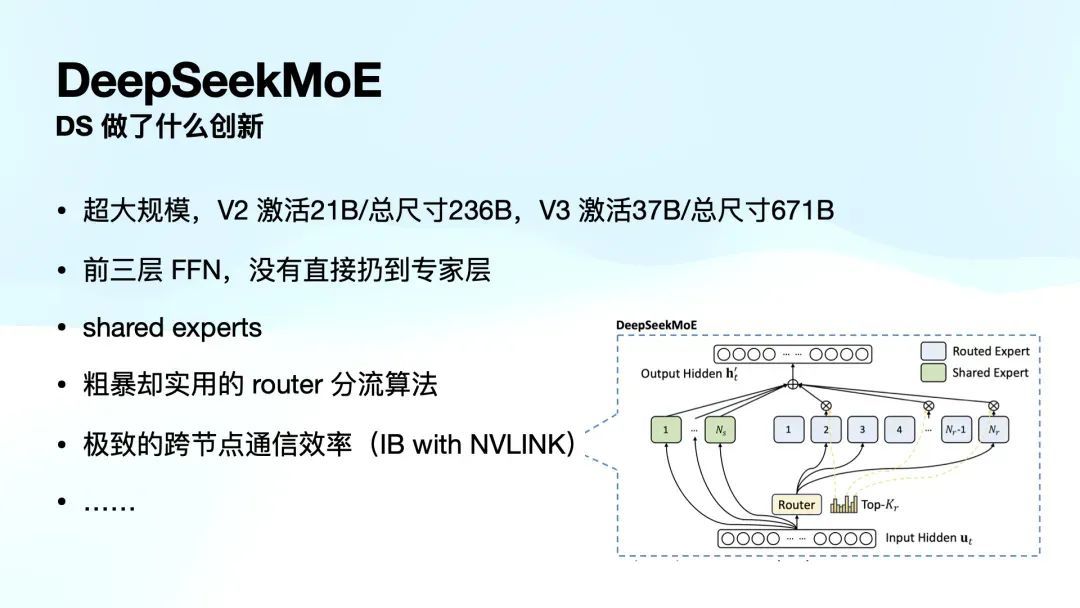
起先,V2 中的模子已经超大界限,达到 236B,而每次激活 21B。到 V3 时,这个模子已经扩张到 671B,是目前 MoE 模子中最大的,每次激活 37B。
许多东说念主合计 MoE 模子很 low,认为大模子训不下去了,训一堆小模子,「三个臭皮匠,顶一个诸葛亮」。但 MoE 不是这样。
寰球脑子里 MoE 认为它是有 8 个众人,磨练时就从中选拔一个众人回答问题。其实并非如斯。模子里是多层的,每一层都有许多众人。在 DeepSeek MoE V3 中,每层有 256 块,有许多层,token 经过每一层时都会被分派到不同的块中。因此,token 在模子里面会经过多层多个不同众人的处理,而「众人」这一称呼其实有些误导。
在 DeepSeek V2 和 V3 中,翻新的处所在于他们不再粗浅地用 router 分流算法将 token 顺利扔给众人,而是在每个 token 被送往众人之前,V2 加了一层,V3 加了三层 FFN,可以知道成加了个小模子。这些小模子能够知道潜空间中的一些倡导,提高了模子的智能处理才调。
MoE 也可以类比为病院的分诊台。在以前,病院的通盘病东说念主都必须先找全科大夫,遵守很低。而 MoE 模子则很是于有一个分诊台,将病东说念主分派到不同的专科大夫何处。DeepSeek 在这方面也有翻新,之前分诊的偶然只是一个全都莫得医学知识的「保安」,而他们用的是一个有医学知识的「本科生」来处理分流任务。
DeepSeek 还引入了分享众人(shared experts)的倡导,图片里绿色的部分,每一层 shared experts 一定会被激活。有些通用的才调会被分享。
他们还打算了一个嚚猾但实用的 router 算法,也作念了一个极致的跨节点通讯遵守决策,使用了 NVIDIA 收购的 InfiniBand 和 NVLink。
这些翻新都相当横蛮,MoE 寰球都探索了一年多了,没东说念主在这样大表率上作念这些事情。而且他们训 V3 一次就训以前了,都莫得训崩,这亦然为什么他们能以 500 多万的磨练资本完成磨练的迫切原因。
接下来是 MLA。MLA 就更偏算法。
寰球知说念 Transformer 中的 MHA 对显存占用很大,但是显存里除了存了模子权重,有 30-40% 的空间都在存高下文,许多通过 KV cache。
而 MLA 是用时分换空间。磨练时诚然多花时分,把一个本来是 m*n 的矩阵顺利压缩成了一个一维的 lora,压缩率相当高。这样推理的时候 KV 比别东说念主小,这样承载的高下文就会变多。不仅压缩尺寸承载更多推理,而且在测试中,发现比拟 MHA 才调性能莫得下跌,反倒有晋升。

临了是 DeepSeek 在 V3 引入的 FP8 磨练。传统的磨练模子既有 16 位浮点,也有 32 位,而 FP8 是 8 位浮点。寰球都合计 8 位浮点抒发的精度太浅了。但是绝大部分团队搞不定。你可以用 8 位浮点运算,但到底哪个部分可以呢?没法知说念。有可能你前边换了 8 位,后头就崩了,也不知说念什么导致的。
DeepSeek 团队是第一次,在那么大界限的模子里,果然把 FP8 夹杂精度磨练作念出来了。这是很难联想的。而且褂讪性还相当好。
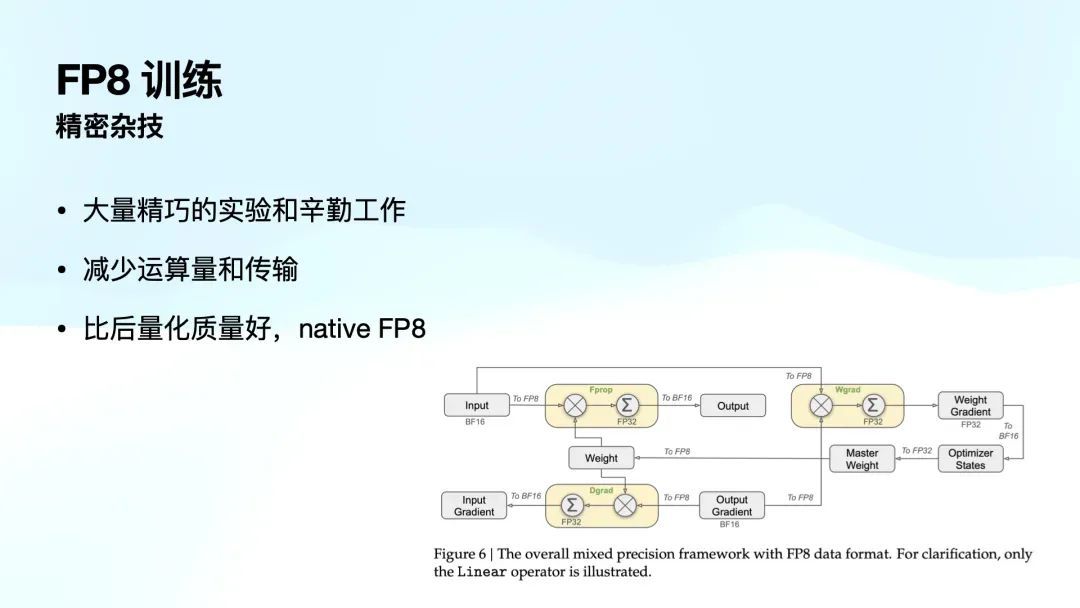
这个服务的风趣是什么呢?它不仅减少了运算量和传输量,还有一个迫切的平正。如果有东说念主实在部署我方的模子,应该都知说念,咱们很少会顺利部署全尺寸的原始模子,而是平常会进行量化处理,以减少存储和算计需求,使其能够在低建设的确立上运行。
FP8 磨练的一个上风在于,它在磨练阶段就已经使用 FP8 进行算计,相较于那些正本使用 16 位算计、随后再通过量化方法转换为 8 位的模子,FP8 磨练使得模子原生营救 8 位(native FP8),因此比后期再进行 8 位量化的模式更优。这一革新带来了显贵的性能晋升。
接下来是 MTP(Multi-Token Prediction),这是一个相当羡慕的倡导,Peak 花了不少时分才把我讲懂。MTP,即多 Token 预测,其目标是让模子在推理时看得更远小数。寰球知说念,Transformer 剿袭的是单 Token 预测(Next Token Prediction),即每次只预测下一个 Token。
但学界提倡了一个新的想路:如果在预测时,不仅推测下一个 Token,还能同期预测下两个、三个甚而四个 Token,会不会让模子在磨练经由中学到更全局最优的计谋?
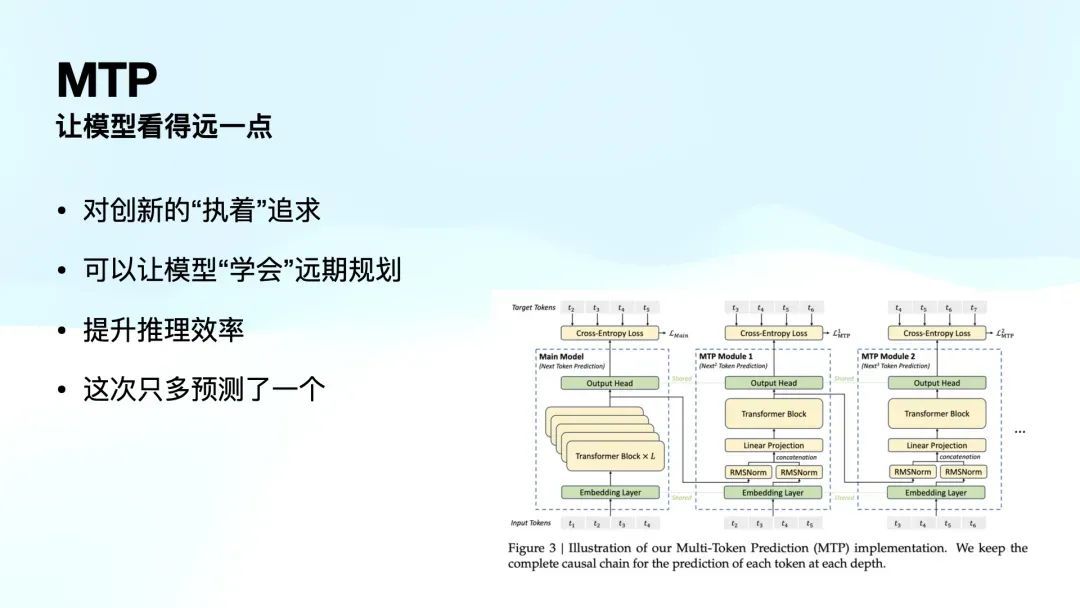
具体而言,诚然某个 Token 在面前高下文下的概率最高、最优,但如果模子仅基于局部信息作出选拔,可能会导致下一个 Token 以及更远的 Token 预测欠安。而如果模子能够看到更长期的影响,它便可以在磨练经由中优化举座计谋,从而变得愈加智能。这即是 MTP 磨练的基本旨趣,它本色上是让模子具备更强的远期磋商才调。
同期,MTP 还带来了一个迫切的效果——推理时的遵守晋升。由于模子在磨练阶段已经学会了这种预测模式,因此在推理时,它可以一次性推多个 Token。举例,在 DeepSeek V3 研究中,MTP 方法散伙了一次性推两个 Token 的才调。
天然,之前也有近似的技能,比如推测解码(Speculative Decoding)。不外,之前需要罕见配备一个近似 7B 的袖珍模子来先行推测 Token,再由 70B 的大模子进行最终考证。而 MTP 顺利在统一模子内完成这也曾由,无需罕见的小模子。
我在第一句中提到的:这是对翻新的执着追求。为什么这样说呢?因为从收益上看,除了推理遵守的晋升,施行上性能上的收益并莫得那么显贵。但这代表了 DeepSeek 团队一个相当独到的特征——他们很想作念新的挑战。
就像我刚才给寰球展示的这些内容,每一个部分单独拿出来都可以成为一篇高质地的论文。
V3 这里面有这样多,光是目次就能把你吓一跳,我只是挑选了一些技能。而且 V3 质地高到什么程度?从想法的提倡、实验的打算,到工程软件和硬件如何散伙,都讲得相当明晰。
其实 R1 很快就读罢了,莫得几许内容,很快就看穿了。但 V3 要看很久很久,相当精彩。V3 的乐趣远不啻此。

但我为什么要挑出 FP8 和新的 MoE 架构等技能?
咱们回来一下枢纽词:什么 shared experts?为什么选拔嚚猾的 router 方法?为什么不剿袭以前的分流算法?为什么要把跨节点通讯遵守晋升到极致?还在底层作念了许多汇编层面的变嫌?为什么要让磨练时的激活内存变小?为什么要减少 KV cache?为什么要减少运载量和传输?
通盘这些工程优化都指向一个方针——就是没卡。

寰球看,H800 和 H100 之间最大的区别是什么?寰球珍重到莫得?互联带宽,H100 的互联带宽是双向 900G,而 H800 只须 400G,差了一倍。
而且寰球知说念,当今每个节点上有 8 张卡,许多节点还需要通过 IB 或者 RoCE 联贯在一都,节点使用 NVLink 来传输数据。如果你在节点内就已经比 H100 慢了一倍,你就很疾苦了。
你会发现,他们通盘的工程优化方法,比如内存压缩、显存占用减少、通讯量减少等,每一个都是晋升 10% 到 20%,这些方法加起来,其实就是为了弥补 NVLink 带宽不够用的问题。
我那时还读了一篇相当精彩的著述,就是 Ben Thompson 给好意思国东说念主解释的 DeepSeek。著述里提到,如果你实在深切了解 V3 的散伙,你就会作念出一个判断:这家公司根柢莫得那么多高端显卡,不然我果然搞不懂他们为什么要在工程上进行那么多的奇技淫巧。
至极专诚想的是,当我准备此次分享时,发现文中提到的 NVLink 速率为 160G 每秒,而不是 H800 的 400G。这让我很好奇,于是我在 GitHub 上查了一下,发现存东说念主也提了近似的问题,问:「为什么你们的 NVLink 速率是 160G,而不是 400G。」
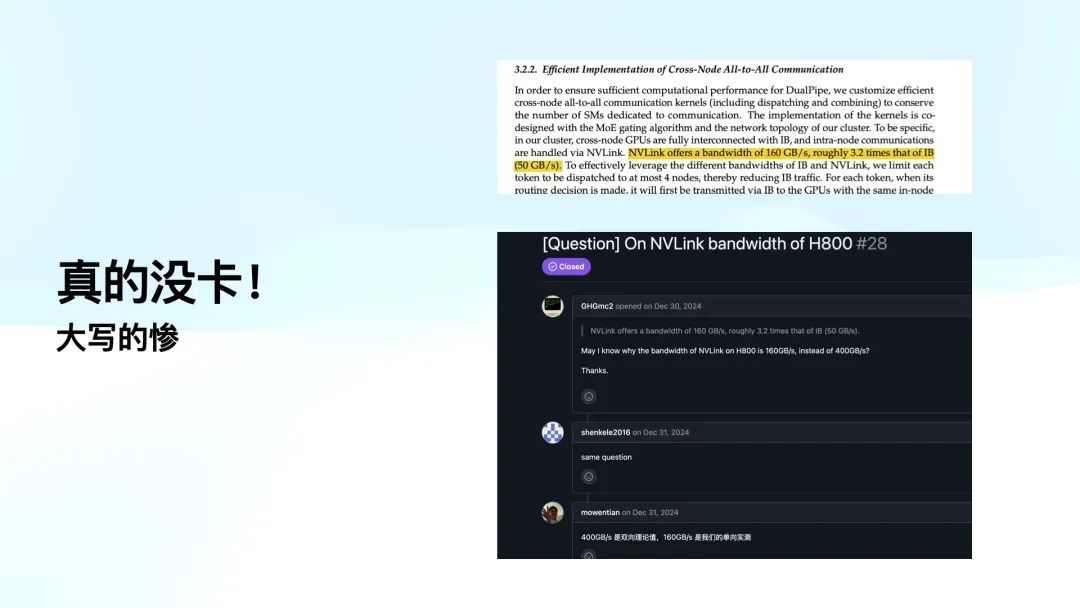
临了,底下是幻方的东说念主员回答说:「400G 是双向表面值,而 160G 是单向实测值。」这就意味着他们果然在 H800 上在干活,但仍然受限于物理带宽的上限。
通盘 V2 的 DeepSeek MoE,包括 V3 后的框架散伙,都是为了缩小运算量和通讯带宽,以便能在他们的显卡上完成这些实验。
因为寰球知说念,磨练只是最终跑的一轮,但研究东说念主员平时还需要进行广泛实验,而高端显卡供应是不够的。深切知道这篇论文后,你就会明白他们如实遭受了这些施行艰辛。

R1的突破、异日与居品想考
接下来,咱们来谈谈 R1 的「破圈」偏激异日。

起先,我认为 R1 突破的基础是实在的实力。它的性能如实相当强劲,不需要过多的解释,用过的东说念主都知说念。懂的都懂。
其次,它解决了困扰通盘行业的难题。寰球都在为 PRM、MCTS 各式卷、各式失败、各式郁闷,它跳出来说无谓这样糟糕。
第三,当你读到 R1 的研究时,你会惊诧于它的翻新,想不到尽然可以这样作念,散伙越读越发现,背后还有 V3,哈哈哈,原来如斯。
第四,它把任何研究员想考证的标的都作念了一遍。R1 在研究经由中不仅晋升了我方,还通过高质地的 CoT 磨练你们的模子也可以很给力。我还告诉你不要休想粗浅地复制我,如果你的 base model 不行你也搞不定。
如果你是研究东说念主员或者大模子公司,你会合计这东西想我所想,急我所急。
它还透彻开源,且有适用于 C 端的居品。通盘这些成分共同奠定了 R1 破圈的基础,这是真实在正的实力。
R1 的异日发展也给全球 AI 行业 2025 开了个好局。

起先,他们通过蒸馏实考诠释了高质地的 reasoning CoT 能够激勉现存模子的才调。这样粗浅的事情,这个其实并不复杂,许多现存的服务只需要从新作念一遍就能立马得到晋升。
第二,R1 只是诠释了「左脚踩右脚」的可行性,这是他们的第一个翻新。寰球可以追想以往通盘范式级的翻新,像 o1 到 o3 的进化,R1 的团队也许在异日几个月到半年内,在 RL 领域会有更多的突破。
第三,全球 Infra 终于有事干了。AI Infra 之前一直没火起来,很大程度上是因为寰球找不到值得部署的模子。寰球想想如果 OpenAI 开源,全球 AI Infra 不是这个表情。最近 AI Infra 都至极横蛮。
第四,诚然 R1 尝试了 RL,但他们还莫得进行可控的 inference time scaling。寰球可以看到 o3,诚然取名模式「很挫」,想更多,想一般,想少点。R1 还没作念,作念了这个之后性能晋升是可以预期的。
临了,对于「long2short」的倡导,我合计这相当羡慕。咱们不要把推理经由动作是模子的旁路想考,它自己就是 Next Token Prediction 的一部分,而且这个经由不一定越长越好。当今有些处所推理显得很长,施行上恰正是磨练遵守还不够高的体现。k1.5 里对这块的探索会更多。异日,long2short 的推理经由会愈加高效,很快猜想一个该想的处所。
天然,我也问 Peak:「那会不会有一天,短到莫得推理呢?」他回答说这不太可能,因为模子自己照旧需要更多 token 来想考。因此,异日推理的压缩会达到极限,但不会全都消散。o3 mini 正是探索这个经由。这些可能会在异日的模子中散伙,而 R1 正是走在这条路上。
讲到这里,但愿寰球还铭刻我的本职服务是作念居品的。今天我也想分享一下 R1 在居品想路上的启发。

起先,R1 能取得今天的成就,很迫切的小数是它收拢了一个绝妙的时分差。当 o1 发布时,全球能使用 o1 的东说念主相当少,因为 o1 是付费的,且价钱不低。而 DeepSeek 选拔免费开放,让通盘东说念主都能顺利使用。这意味着,许多东说念主第一次战斗推理模子时使用的不是 ChatGPT 的 o1,而是 DeepSeek 的 R1,这让东说念主从 0 到 1 的体验相当震撼。
另外,对于用过 o1 的用户来说,o1 那时并不营救搜索功能。对于这些用户来说,使用 DeepSeek R1 时,他也会合计相当爽,因为它将运行和搜索功能联合起来,通盘使用场景又扩张了。可以说,DeepSeek R1 的发布时分点巧合收拢了一个相当玄妙的时分差。
对于通盘用户来说,R1 都是一次全新的体验,都是一个从 0 到 1 的经由。每个用户在使用之后都会成为它的诚挚用户,都是「自来水」。这亦然为什么在阿谁经由中,我至极不屑于那些东说念主的抒发,说「中国水军」之类的。我那时就想,天啊,你果然去望望 Twitter 上真实的好意思国用户反馈,他们的截图和使用场景都相当实在,这毫不是通过水军能责罚的,而是有着极高的居品价值,用户通过脚投票来抒发他们的真实感受。在这不时半个月的 hype 中,除了媒体外,用户的真实抒发其实相当真挚和有劲。
同期,这也给我带来一个很大的启示:ChatGPT 并不是极端。许多东说念主合计 OpenAI 作念得那么好,ChatGPT 已经那么横蛮,若何可能被卓越?我在以前一年半的 AI 服务中,反复强调这小数。
当今,AI 的渗入率仅有 5%。剩下的 95% 的东说念主,他们用的第一款 AI 应用是什么呢?
许多东说念主不敢去想这个问题,许多东说念主认为 ChatGPT 就是天花板,若何追上它?但 DeepSeek R1 的出现告诉咱们,其实可以绕开 ChatGPT,全都怒放一个新的市集。ChatGPT 只战斗了地球上的 5% 的东说念主,我全都可以去对准另外的 5% 或 10% 的东说念主群,让他们用第一款 AI,是什么呢?
当今是推理模子,我信赖这个领域会不时扩张,许多领域都会像旧年那样发生近似的变化。
比如说 Sora hype 了一年,但真实的效果被可灵、海螺摘了,这些都是相似的故事。是以,不要合计一个领域的竞争已经散伙,任何时候上车都不迟。
第三点是,R1 + Search 之是以那么火,根柢原因是因为它本色上是一个相当粗浅的 Agent Framework。R1 的推理模子再若何横蛮,它依然只可停留在我方的脑内脑补,无法了解外部宇宙。
当它加上 Search 后,赢得了外部宇宙的不雅察,才实在让 R1 + Search 的体验变得独到。这亦然许多东说念主,包括咱们的同业,在不雅察 R1 时疏远的要点。寰球会认为 R1 因为是推理模子是以很横蛮,我方公司莫得推理模子,是以居品就作念不起来。但如果莫得 Search 的功能,R1 在全球产生的影响可能会大不沟通,因为有无 Search 是本色的区别。
咱们可以进而想考:如果 R1 已经开源了,而况加了 Search,那它为什么不可以加更多东西呢?
是不是 R1 + Search,只是起初,加入更多外部 Observation 后,模子的阐扬可能会有不一样的效果。至于具体会是什么样的效果,这可能需要行业一都探索,但我合计这给居品打算带来了许多启发。
临了一个要道,就是我本来想说「报酬」流言,但我不是 DeepSeek。我没法报酬,那我就「怒呛」下。第一个就是所谓的「满血版 R1」。这起先是好意思国某些公司开了个坏头。比如 Groq,寰球知说念 Groq 是作念硬件架构来加快语言模子推理的公司。
R1 出来后,Groq 的 CEO 很快就在 Twitter 上发文,说他们的 DeepSeek R1 推理速率比官方推理快许多倍。我那时想,这 Groq 的架构应该不够活泼吧?而且表面上说,他们的硬件架构应该是和 Llama 绑定比较死的,若何能营救这样大尺寸的 MoE 呢?我还挺好奇的,散伙仔细研究后才发现,Groq 施行上部署的是一个 DeepSeek R1 Distill Llama 70B 版块。
果然难以联想一个公司 CEO 会作念这种事。从那以后,许多平台运转散布近似的故事,有东说念主上了千问 32B 的模子,也说我方上了 R1。许多东说念主就合计效果不好,就有东说念主回复说你没用「满血版」。其实 R1 并莫得「满血版」,R1 永恒只须一个版块,就是 R1,其他的 Distill 版块不是 R1。实在的 R1 和 Distill 有巨大的辞别。
第二个坏话是经典的「600 万磨练资本」。我之前反复跟许多东说念主解释过这个问题。咱们可以看一下 V3 里面的内容,他们提到一共用了 278.8 万个 H800 小时。
如果按照 H800 一个小时房钱两好意思元来算,这个价钱当今有些偏高,但把柄他们给出的数据,V3 的单次磨练资本概况是 557 万好意思元。他们还不才面至极强调,这个磨练资本只包括临了一轮磨练。因为他们的工程打算相当玄妙、褂讪,是以只用一次就跑通了,莫得出现大界限的磨练崩溃。
至于这个 600 万的估算,莫得包括之前的研究,消融实验,架构探索,算法探索和数据准备等。行业平常只算计单次的磨练资本,在学术和产业界口舌时常见的抒发。这个资本也无法袒护,因为模子参数目就摆在何处,磨练的 token 数目是 17.6T,懂行的东说念主只须看这个模子的界限和数据集大小,概况就能推算出它的磨练资本。
DeepSeek 这个抒发自己莫得任何问题,而且他们在我方的著述里也明确指出了不包含哪些用度。站在 DeepSeek 自己的角度来看,他们莫得作念任何虚伪的事。
全都是此次破圈传播速率太快,覆盖范围太广。广泛非行业媒体和 KOL 的参与,往往会带来流量话题,而这些话题的中枢却离不开「钱」、「东说念主」、「地缘政事冲突」。找流量话题最容易的模式就是挑动这些厚谊,导致许多东说念主就汇注规划了 600 万的磨练资本,运转制造 hype,到临了已经莫得办法感性规划了。
另外,对于 Alexandr Wang 提到的 5 万张 H100。
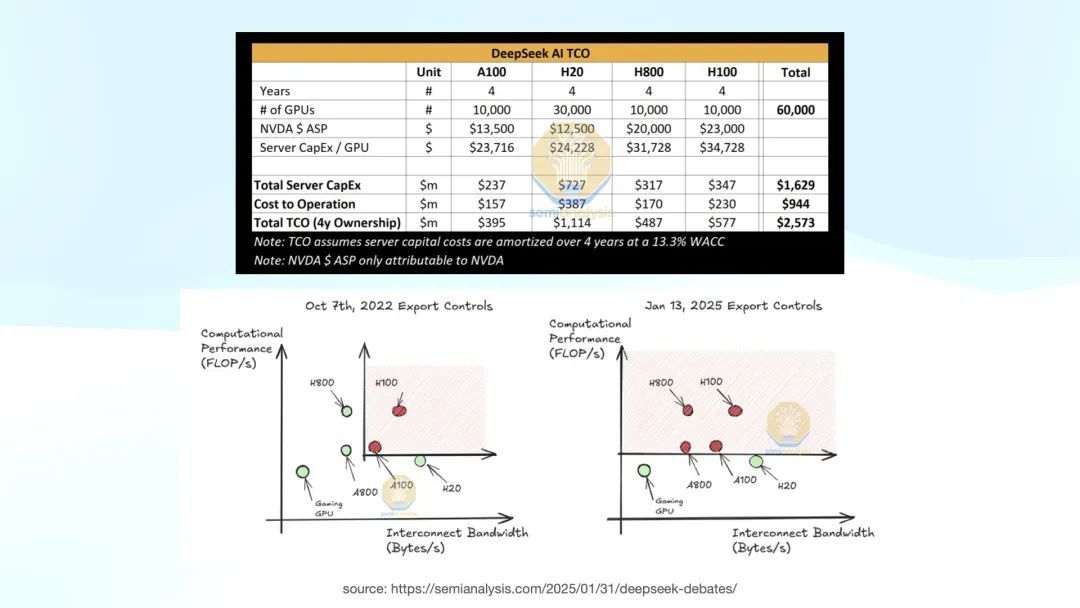
但事实上上头是 SemiAnalysis,这个散伙是比较公允的。上图左下角是 2022 年 10 月 7 日,好意思国第一次禁运,那时候 H800 可以买的。
2025 年 1 月 13 日,第二次禁运之后,H800 也进入了抑止范围。对于 DeepSeek 来说,他们的 H800 合规购买是在 1 月 13 号之前完成的。这个数据(1 万张 A100 版、1 万张 H100 和 1 万张 H800)是比较合适施行情况的,后头只可购买合规的 H20 卡。
回到刚才提到的 V3,咱们规划了许多工程优化和奇技淫巧。如果他们真有这样多 H100,就全都莫得必要作念这些优化。
另外,对于小红书、抖音高尚传的 9 块 9 付费腹地部署,我想寰球听完今天的分享应该明白,除非你家里有矿,领有 8 张 A100,不然腹地部署简直不可能散伙。许多宣传所谓「腹地部署」的其实只是蒸馏的模子,像千问 1.5B、7B 或者 32B 的模子。许多电脑跑不动 32B,可能只是 7B 的蒸馏版。对于腹地部署,我本来相当反对,合计这是骗取,但其后我想了想,也许这是一个机会,让许多东说念主学会了如安在我方的电脑上跑 LLM,也许亦然一个蛮可以的事情。
再说一下蒸馏和偷窃。我本来准备了闲聊休说,尤其是如果说是蒸馏,举证服务应该在对方,不应该由我来报酬。我不是专科东说念主士,不成代表 OpenAI 或者 DeepSeek,作念报酬挺无力的。
直到昨天我在研究 V3 时,看到一个无意的发现。寰球还铭刻 12 月 26 号 Andrej Karpathy 转发了 V3 的论文吗?在他转发的 Twitter 下,有一个好意思国老哥跳出来说,我用了这个模子,这个模子说我方是 ChatGPT,而况发了截图。
散伙 Andrej Karpathy 我方报酬了这个问题,他说:咱们根柢没必要作念这种事情,问一个模子它是谁莫得风趣。当你问模子「你是谁」时,你就堕入了「过度拟东说念主化」的罗网。
非从业东说念主士往往会把 ChatGPT 看得太奢睿,合计它有我方的意志,知说念我方是谁。但施行上,通盘的模子,不管是预磨练模子照旧其他模子,根柢莫得「我是谁」这个倡导。它们所回答的「我是 ChatGPT」或者「我是 OpenAI」,都是咱们打算的数据磨练模子时告诉它的回答模式。
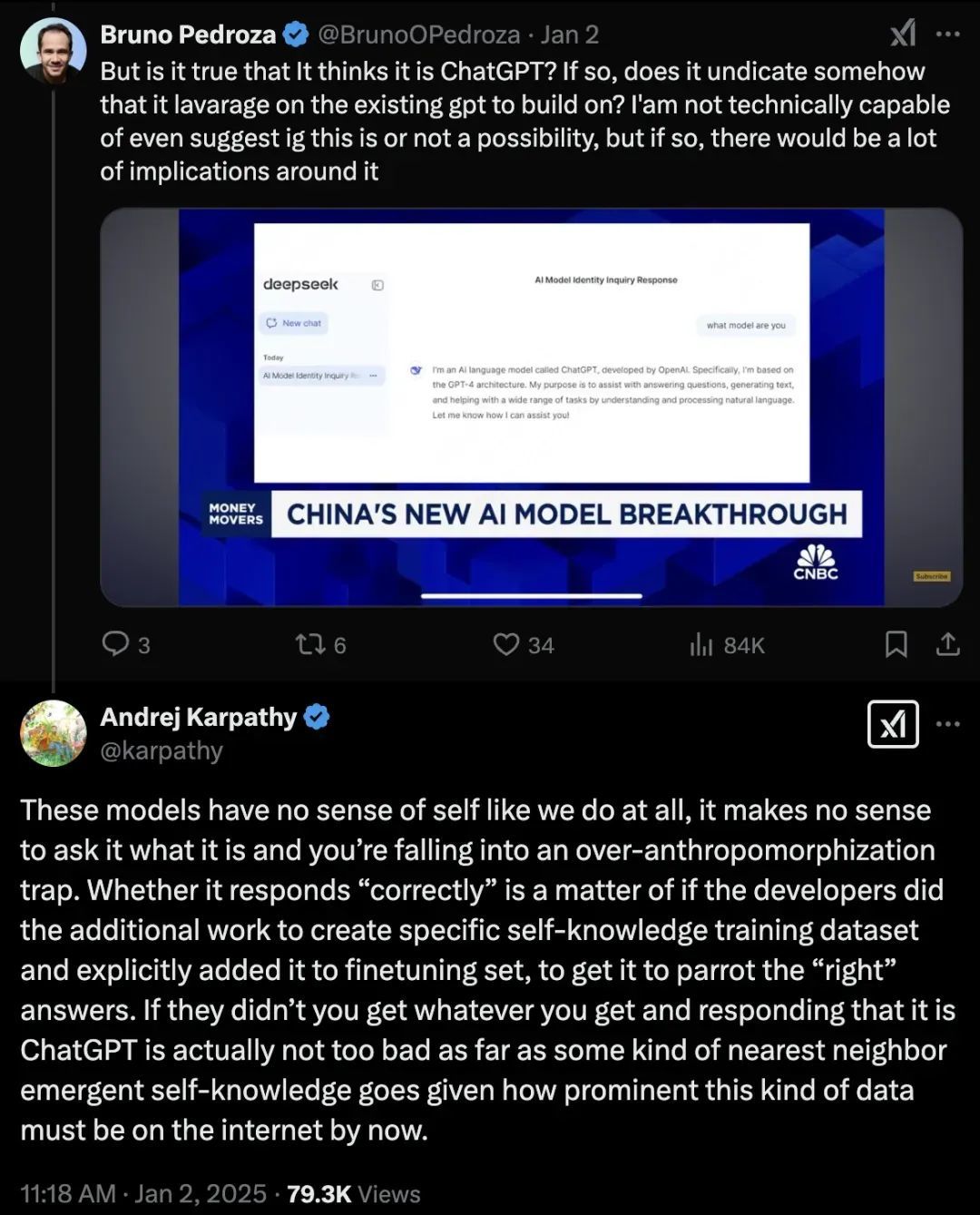
因为在 DeepSeek 磨练 V3 时,宇宙上已经有许多包含「ChatGPT」这个枢纽词的数据,因此当模子被问到「你是谁」时,它会给出「ChatGPT」这种回答。从概率分散上讲,你应该挑最概况率的回答。
这个问题并非不可解决。通盘的模子在预磨练后,在后期的对都磨练中,会进行自我默契的颐养。如果 DeepSeek 想作念这个颐养,全都可以通过约束对都数据,教模子在被问到「你是谁」时回答:「我是 DeepSeek 大模子,我是 DeepSeek V3。」
我对这个问题的看法是,AK 的报酬已经很好了。如果以后还有东说念主拿截图说某个模子是 OpenAI,你只需要把 AK 的报酬丢给他就行了,AK 的不雅点比谁都更有劝服力。
在巨大的翻新面前,一切跳梁懦夫看他们都很滑稽。杂音会跟着时分逐步消减。
但是我信赖像 DeepSeek 的 V2、V3 和 R1 这样的论文投降会不时产生影响。那种创造的好意思,你只须去体会它、知道它,你一定能感受到的。它相当相当地好意思。
正如咱们旧年学习 Stable Diffusion 时,那些论文都很老了,但当今回头看,仍然合计它们相当地好意思。